Recursive Failure Archaeology: RLM for Agent Failure Diagnosis
Authors: Mohammed Alshehri
Year: 2026
TL;DR: RLM turns agent failure analysis from one-shot diagnosis into an auditable investigation process, with especially strong localization of the earliest causal failure in long SWE-agent traces.
- Compares recursive investigation against full-context GPT-5.5 on 15 official tau2 retail traces.
- Shows reliable structured reports with 1.000 parse success and 0.000 false-positive failure rate on the tau2 slice.
- On long SWE-agent traces, RLM localizes the first causal failure much more closely than the full-context baseline.
- A staged RLM-style failure archaeology pipeline: segment analysis, hypothesis generation, evidence pruning, control verification, and final adjudication.
- A benchmark protocol comparing report quality, evidence recall, evidence precision, causal anchors, control correctness, and first-failure localization.
- A long-trace SWE-agent stress test showing that recursive investigation is most useful when the target is earliest causal failure, not broad summary.
This project studies Recursive Language Model style investigation for agent failure archaeology. Instead of asking GPT-5.5 to read an entire trajectory in one prompt, the system externalizes the trace as structured data, inspects selected segments, stores intermediate evidence, generates competing hypotheses, prunes evidence, verifies whether a real task-level failure is proven, and then writes a normalized final report. On short tau2 retail traces, full-context GPT-5.5 remains slightly stronger overall, but RLM is close on semantic root cause and causal consistency while producing auditable intermediate artifacts. On long SWE-agent traces, RLM shows its clearest advantage: substantially better localization of the earliest causal failure.
Comparing Recursive Investigation With Full-Context GPT-5.5
I wanted to test a simple idea: instead of giving GPT-5.5 an entire agent trace and asking “what went wrong?”, can I make the model investigate the trace recursively?
The project became a small experiment in failure archaeology. The input is a long agent trajectory. The output is a report that tries to identify where the failure began, how it propagated, and which events support the diagnosis.
The core comparison was:
| Method | What it does |
|---|---|
| Full-context GPT-5.5 | Reads the whole trace in one prompt and writes a diagnosis. |
| RLM | Breaks the trace into segments, analyzes local evidence, generates hypotheses, prunes evidence, verifies failure/control status, then writes the final report. |
I ran both methods on the same 15 official tau2 retail traces.
The working hypothesis was not that RLM would automatically beat GPT-5.5. The more realistic hypothesis was narrower: RLM might produce a more inspectable diagnosis, because the reasoning process is decomposed into explicit stages instead of hidden inside a single long prompt.
The RLM Idea I Used
The RLM paper’s main idea is that long context should not always be treated as text stuffed into a single prompt. Instead, the long input can live outside the model as an environment, and the model can inspect pieces of it recursively.
The useful ideas for this project were:
| RLM paper idea | How I used it |
|---|---|
| Externalized context | The full trajectory lives as structured JSON, not only inside one model prompt. |
| Symbolic intermediate state | Segment analyses, hypotheses, pruned evidence, and verifier outputs are stored as JSON artifacts. |
| Recursive inspection | The system opens selected trajectory segments instead of always reading everything at once. |
| Final synthesis | A root model uses the intermediate artifacts to produce the final report. |
For this project, the mapping is:
| RLM concept | Failure archaeology equivalent |
|---|---|
| Long prompt | Agent trajectory |
| REPL/context environment | Local dataset + trajectory schema |
| Sub-calls | Segment analysis calls |
| Intermediate variables | Evidence, hypotheses, control verdict |
| Final answer | Failure archaeology report |
So the point was not to make a chatbot with a longer prompt. The point was to build a small investigation loop.
This distinction mattered in practice. Full-context prompting can produce a good final answer, but the reasoning process is mostly implicit. RLM produces additional artifacts that can be inspected after the run: which segments were selected, what each segment analysis found, which hypotheses were considered, which evidence was pruned, and whether the verifier believed a real task-level failure had been proven.
The Pipeline
The RLM pipeline I implemented looks like this:
flowchart TD
A["Agent trace"] --> B["Trajectory schema"]
B --> C["Signal detection"]
C --> D["Segmentation"]
D --> E["Segment analysis"]
E --> F["Competing hypotheses"]
F --> G["Evidence pruning"]
G --> H["Control verification"]
H --> I["Final report"]
The most important design decision was separating evidence discovery from final judgment. Early versions of recursive analysis can collect many suspicious events, but suspicious does not always mean causal. That is why I added a verifier step before the final report.
Here is the core implementation shape from the investigator:
selected = self.select_segments(segment_map, limit=segment_limit)
analyses = [
self.analyze_segment(trajectory, signals, segment, live=live)
for segment in selected
]
hypotheses = self.generate_hypotheses(trajectory, analyses, live=live)
pruned_evidence = self.prune_evidence(
trajectory,
analyses,
hypotheses,
live=live,
)
control_verdict = self.verify_control(
trajectory,
hypotheses,
pruned_evidence,
live=live,
)
report = self.final_judge(
trajectory,
hypotheses,
pruned_evidence,
control_verdict,
live=live,
)
That code is the whole idea in miniature: inspect, hypothesize, prune, verify, judge.
The pipeline produces these artifacts for every trace:
| Artifact | Purpose |
|---|---|
| Selected segments | The parts of the trace the recursive investigator decided to inspect. |
| Segment analyses | Local findings from each selected segment. |
| Competing hypotheses | Multiple possible explanations, including a no-failure/control hypothesis. |
| Pruned evidence | The smallest event set considered sufficient for each hypothesis. |
| Control verdict | A separate decision about whether a persistent task failure was proven. |
| Normalized report | The final root cause, causal chain, evidence, confidence, and interventions. |
| Causal graph | A graph representation of the final causal explanation. |
That is why I think of RLM less as a prompt and more as an experiment harness for trajectory reasoning.
Segment Analysis
The first model calls are local. A segment analyzer only sees a selected region of the trace and has to return compact JSON.
The prompt rule is intentionally narrow:
SEGMENT_ANALYSIS_SYSTEM = """You are a sub-investigator in a recursive failure archaeology system.
Analyze only the provided segment. Do not invent events that are not in the segment.
Return compact JSON with:
- segment_id
- local_findings
- causal_clues
- memory_issues
- likely_failure_role
- confidence
"""
This is directly inspired by the RLM paper’s “inspect a slice, store the result, continue” pattern. The segment model is not supposed to solve the whole trace. It only contributes local evidence.
In the implementation, the segment limit is also important. For this run I used --segment-limit 4, which means the recursive investigator could inspect only a small number of selected trajectory regions. This creates a useful pressure: if the selector chooses poor segments, the final report suffers. That makes segment selection a real component of the method rather than just formatting.
Hypotheses, Pruning, and Control Verification
After local analysis, the root model generates multiple possible explanations. I found this important because a trace often has several plausible stories:
- a tool failed
- the agent escalated too early
- the user gave incomplete identity information
- nothing actually failed and the trace is a successful control
The hypothesis generator is forced to include a no-failure/control hypothesis:
HYPOTHESIS_GENERATOR_SYSTEM = """You are the hypothesis generator for a Recursive Failure Archaeology pipeline.
You are given trajectory metadata, task outcome, detected signals, and local segment analyses.
Your job is to produce competing hypotheses, not a final report.
Rules:
- Always include one explicit no-failure/control hypothesis.
- Include 2-4 failure hypotheses when evidence exists.
- A suspicious event is not enough; each failure hypothesis needs task-level consequence.
"""
Then the evidence pruner tries to reduce noise:
EVIDENCE_PRUNER_SYSTEM = """You are the evidence pruner for Recursive Failure Archaeology.
Your job is to reduce noisy local findings into a minimal evidence set for each hypothesis.
Rules:
- required_event_ids should be the smallest sufficient set, usually 2-5 events.
- Exclude events that are merely noisy, downstream, or redundant.
- Preserve contradicting evidence for the control verifier.
"""
The verifier is the guardrail. It asks whether a persistent task-level failure has actually been proven:
CONTROL_VERIFIER_SYSTEM = """You are the no-failure/control verifier for Recursive Failure Archaeology.
Your job is to answer: has a persistent task-level failure been proven?
Rules:
- Prefer no_persistent_failure when the task outcome is successful and no concrete unmet requirement is proven.
- Do not count a tool error, clarification, or inefficiency as a failure if the user task was eventually resolved.
- A failure is proven only if evidence shows an unmet user request, wrong state change, policy violation, or unresolved escalation.
"""
This is the part that made the method feel more serious. Without a control verifier, the system can become too eager to call every suspicious event a failure.
The final judge then receives the hypotheses, pruned evidence, and verifier output. Its job is not to restart the investigation from scratch, but to adjudicate between already-structured intermediate results:
report = self.final_judge(
trajectory,
hypotheses,
pruned_evidence,
control_verdict,
live=live,
)
This is the closest part of the system to the RLM paper’s final synthesis step: the model does not need to remember every raw event, because important intermediate state has already been externalized.
The Experiment
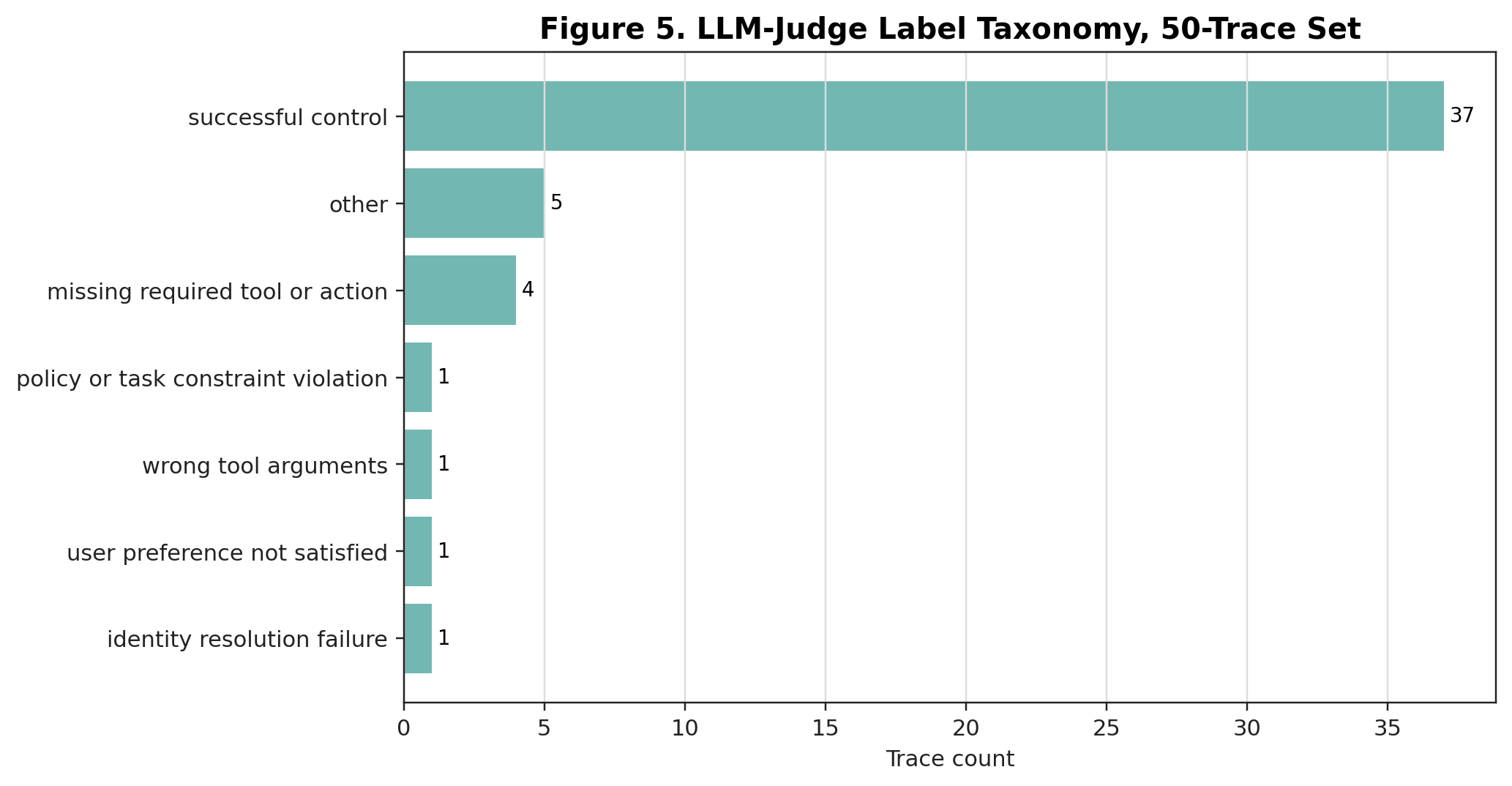
I used 15 official tau2 retail traces from the prepared 50-trace set. Each trace had a GPT-5.5 LLM-as-judge causal label. These labels are not human-gold annotations, so I treat the result as an experimental benchmark rather than a final scientific claim.
Both methods used GPT-5.5:
| Method | Root model | Segment model |
|---|---|---|
| RLM | GPT-5.5 | GPT-5.5 |
| Full-context baseline | GPT-5.5 | none |
I kept both methods on GPT-5.5 to avoid making the comparison about model quality. The difference was the reasoning structure: recursive investigation versus direct full-context diagnosis.
The evaluation metrics were:
| Metric | What I used it to check |
|---|---|
| Semantic root cause | Did the predicted cause match the label semantically? |
| Causal consistency | Did the explanation actually support the final outcome? |
| First failure turn error | Did the method locate the beginning of the failure? |
| Evidence recall | Did it recover the labeled evidence events? |
| Evidence precision | Were the cited events actually useful evidence? |
| Causal anchor recall | Did it recover the most central causal events? |
| Control correctness | Did it correctly identify no-failure traces? |
| False positive failure rate | Did it invent failures on successful controls? |
| Parse success | Could the report be normalized into the schema? |
The live RLM run:
.venv/bin/python scripts/run_investigator_batch.py \
datasets/real/tau2_official_retail_50 \
--experiment-id phase_18_rlm_gpt55_live_15 \
--limit 15 \
--segment-limit 4 \
--root-model openai/gpt-5.5 \
--segment-model openai/gpt-5.5 \
--root-max-tokens 3000 \
--segment-max-tokens 900 \
--resume \
--live
The benchmark:
.venv/bin/python scripts/run_scientific_benchmark.py \
datasets/real/tau2_official_retail_50 \
--investigation-dir datasets/real/tau2_official_retail_50/experiments/phase_18_rlm_gpt55_live_15/investigations \
--method-id rlm_gpt55_live_15 \
--label-file datasets/real/tau2_official_retail_50/llm_judge_labels.json \
--output datasets/real/tau2_official_retail_50/experiments/phase_18_rlm_gpt55_live_15/benchmark_15.json
Results
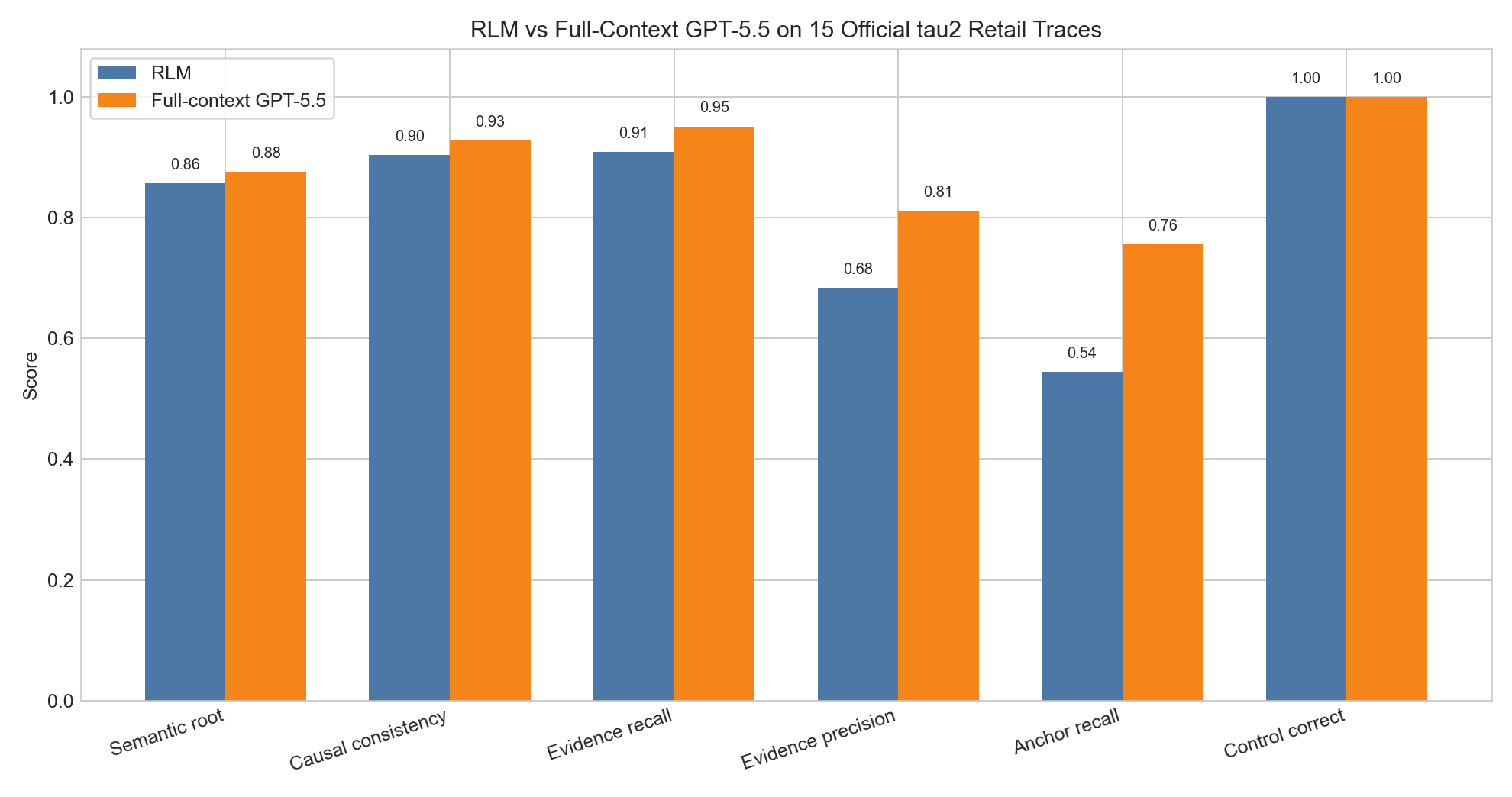
| Metric | RLM GPT-5.5 | Full-context GPT-5.5 |
|---|---|---|
| Semantic root cause | 0.8571 | 0.8762 |
| Causal consistency | 0.9038 | 0.9272 |
| First failure turn error | 0.0667 | 0.0000 |
| Evidence recall | 0.9089 | 0.9511 |
| Evidence precision | 0.6833 | 0.8111 |
| Causal anchor recall | 0.5444 | 0.7556 |
| Control correctness | 1.0000 | 1.0000 |
| False positive failure rate | 0.0000 | 0.0000 |
| Parse success | 1.0000 | 1.0000 |
Full-context GPT-5.5 is still slightly better on this short-trace slice. That is not surprising. These tau2 traces are short enough for GPT-5.5 to read directly, so the full-context baseline is very strong.
But RLM was close on the main report-quality metrics:
- semantic root cause:
0.8571vs0.8762 - causal consistency:
0.9038vs0.9272 - evidence recall:
0.9089vs0.9511
The bigger weakness was precision:
- RLM evidence precision:
0.6833 - full-context evidence precision:
0.8111
So the main bottleneck is not “can RLM find relevant evidence?” It can. The bottleneck is selecting the smallest and cleanest evidence set.
This result was useful because it showed a specific weakness. RLM did not collapse on root-cause quality, and it did not fail to retrieve evidence. Instead, its weakness was over-inclusion: it cited more evidence than necessary or included context events that were not as directly causal as the full-context baseline’s evidence set.
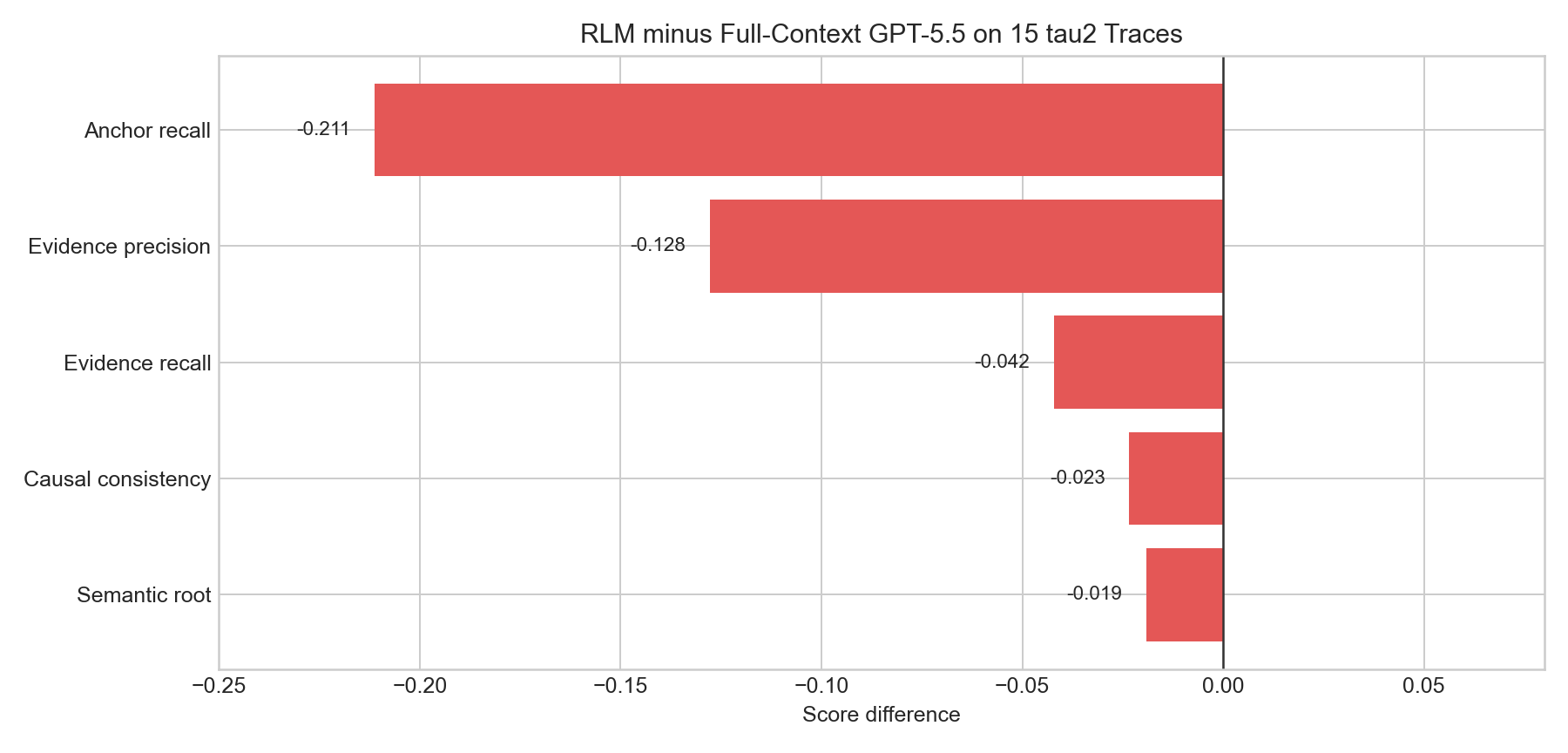
Reliability Result
The part I care about most is reliability:
| Reliability check | RLM |
|---|---|
| Control correctness | 1.0000 |
| False positive failure rate | 0.0000 |
| Parse success | 1.0000 |
| Consistency issues | 0 |
This means RLM did not hallucinate failures on successful controls in this slice. For a failure-analysis system, that matters a lot. A model that finds interesting clues but invents failures would not be useful.
The reliability result is especially important because the system is meant to diagnose failures, not merely find anomalies. A failed lookup, a clarification question, or a transfer to a human can be normal behavior depending on the task constraints. The verifier is supposed to prevent the system from treating every irregularity as a root cause.
Example Trace
One example report came from:
tau2-official-retail-35-trial-0-39d2c249-6e85-4db3-8f36-049be2744cf3
The user wanted to return a speaker and change a laptop order. The task did not complete because identity verification failed.
RLM’s root cause:
The customer record was not found via either email lookup or name/zip lookup, so identity verification and order access failed. Without verified identity, the assistant could not perform the requested return or order modification.
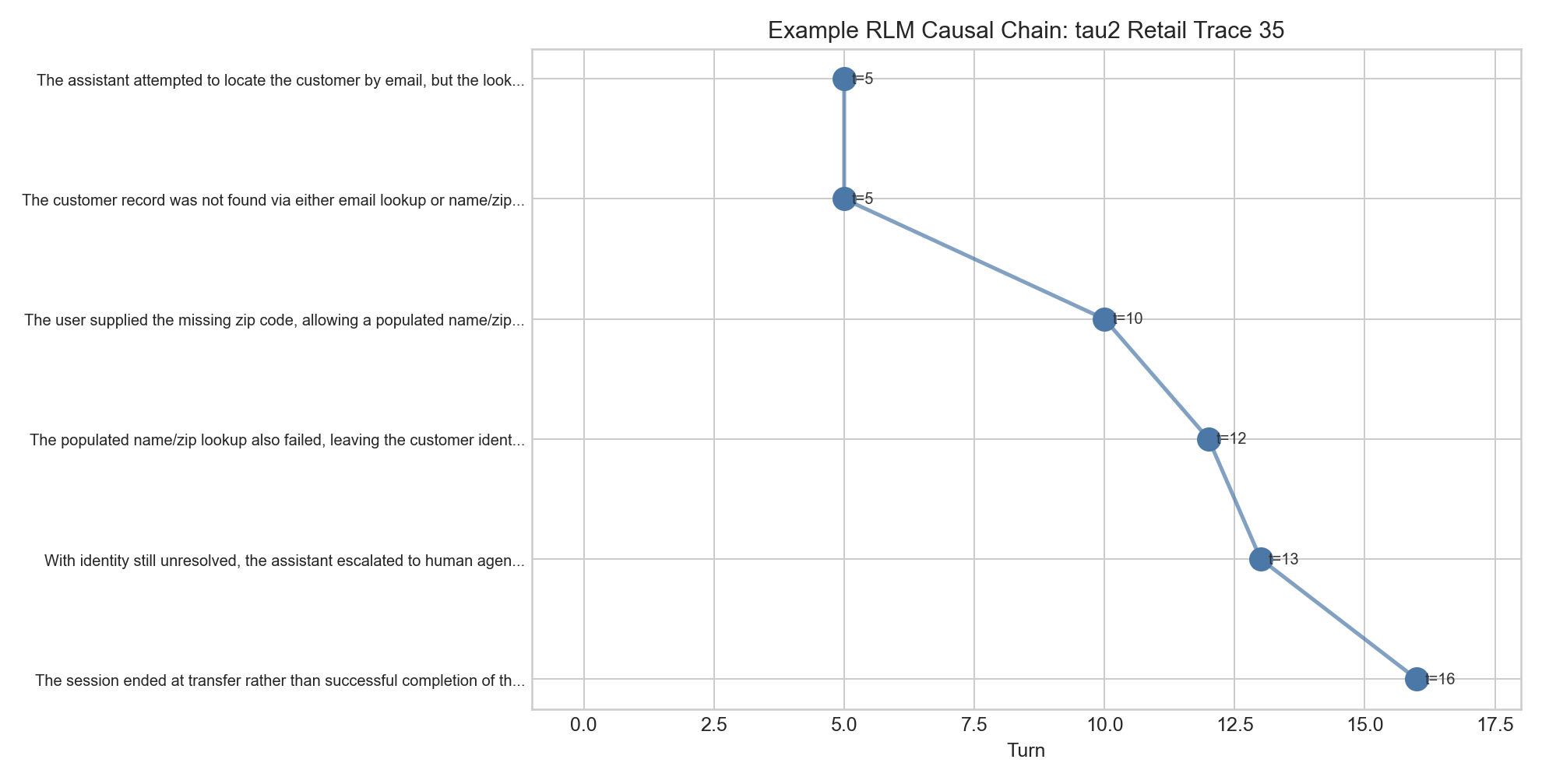
The causal chain was:
| Step | Event |
|---|---|
| 1 | Email lookup failed. |
| 2 | User supplied the missing zip code. |
| 3 | Populated name/zip lookup also failed. |
| 4 | Identity remained unresolved. |
| 5 | Assistant escalated to human support. |
| 6 | Session ended without completing the order actions. |
What I like about this example is that the report is not just “the agent failed.” It separates an agent mistake from a data or identity-resolution blockage. That is the kind of distinction a failure archaeology system should make.
The intermediate hypotheses are what make this example interesting. The system considered at least four possible interpretations:
| Hypothesis | Interpretation |
|---|---|
| Identity lookup failure | The backend/user data could not resolve the customer, blocking order access. |
| Premature escalation | The assistant may have escalated before exhausting available recovery paths. |
| Procedural lookup error | An earlier lookup may have used incomplete zip information. |
| No-failure/control | The assistant may have behaved correctly under identity-verification constraints. |
The final report selected the identity-resolution explanation because the later populated name/zip lookup also failed. That matters: the earlier incomplete lookup was suspicious, but it was not sufficient to prove the root cause once the later complete lookup failed too.
Long SWE-Agent Traces
After the tau2 experiment, I wanted a harder test. The tau2 traces are useful, but they are short enough that a full-context model can simply read the whole thing. The more interesting question for RLM is what happens when the trace is genuinely long.
So I added a small real long-trace experiment using SWE-agent trajectories from AI-ModelScope/SWE-agent-trajectories. I converted a local subset of the 15 longest traces from the first downloaded shard into the project schema.
The resulting traces were much longer than the tau2 examples:
| Dataset | Trace count | Min events | Max events | Mean events |
|---|---|---|---|---|
| SWE-agent long subset | 15 | 525 | 797 | 632.47 |
This changed the problem. The task was no longer just “summarize a failure.” The task became:
In a 500-800 event trajectory, where did the failure actually begin?
That question matters because the final failure is often obvious. The scientific value is in locating the earlier causal turn that made the collapse likely.
Labeling the Long Traces
I did not want to score these traces with placeholder labels, so I added a long-trace judge:
scripts/run_swe_long_llm_judge.py
The judge does not simply dump the entire trajectory into a prompt. It builds a hierarchical packet:
return {
"trajectory_id": trajectory.trajectory_id,
"outcome": trajectory.outcome,
"metadata": {...},
"event_count": len(trajectory.events),
"event_skeleton": event_skeleton,
"selected_events": selected_events,
"packet_policy": {
"selection_features": [
"head_events",
"tail_events",
"error_windows",
"assistant_repetition_windows",
"middle_breadcrumbs",
],
},
}
The important idea is that the judge sees both:
- a compressed view of the full trajectory,
- fuller evidence windows around likely causal regions.
That is closer to how I want the actual system to work: not blind truncation, and not a single undifferentiated wall of text.
The live labeling command was:
.venv/bin/python scripts/run_swe_long_llm_judge.py \
datasets/real/swe_agent_long_15 \
--model openai/gpt-5.5 \
--limit 15 \
--resume \
--live
Validation passed:
Labels: 15
Errors: 0
The label distribution was surprisingly concentrated.
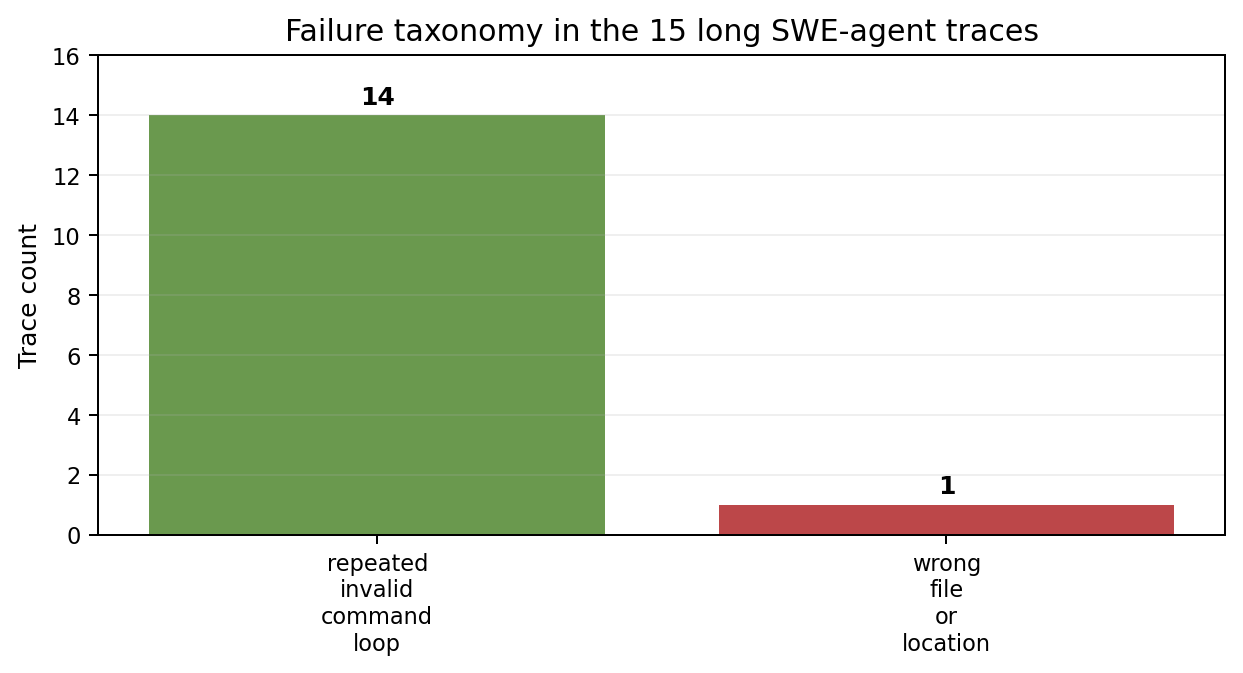
| Failure taxonomy | Count |
|---|---|
| repeated invalid command loop | 14 |
| wrong file or location | 1 |
This is an important limitation. These 15 traces are not a balanced coding-agent benchmark. They are mostly extreme collapse traces where the agent gets stuck repeating malformed commands or operating from a wrong assumption. But that also makes them useful stress tests for long-horizon failure archaeology: the failure begins early and then propagates for hundreds of events.
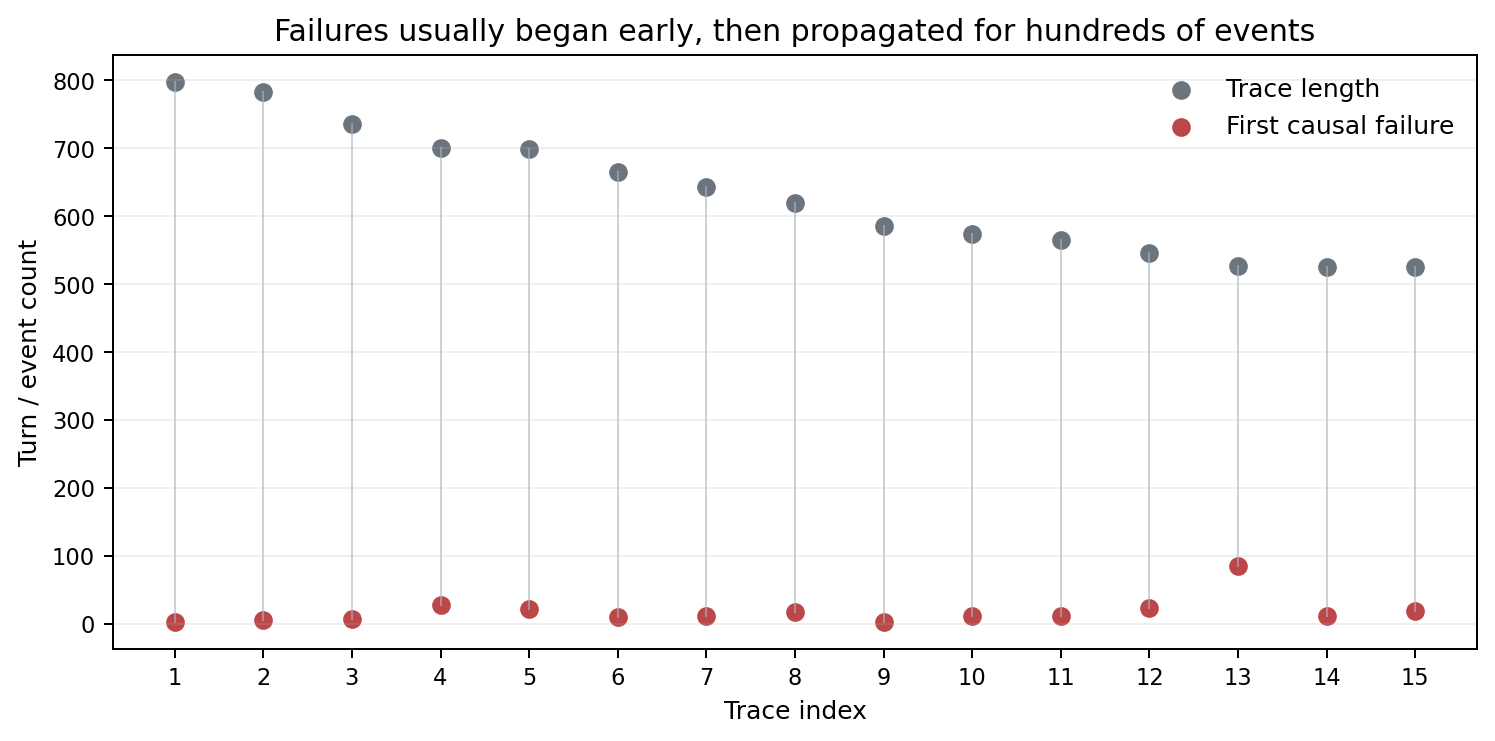
This chart is the clearest explanation of the experiment. The gray dots are the full trace lengths. The red dots are the labeled first causal failure turns.
In most traces, the first causal failure happened very early. The trace then continued for hundreds of events. That is exactly the failure-archeology setting: the collapse is visible at the end, but the cause is buried near the beginning.
RLM vs Full-Context GPT-5.5 on Long Traces
The first RLM run completed 9 of the 15 long traces. I then ran a matched full-context GPT-5.5 baseline on the same first 9 traces and scored both against the new labels.
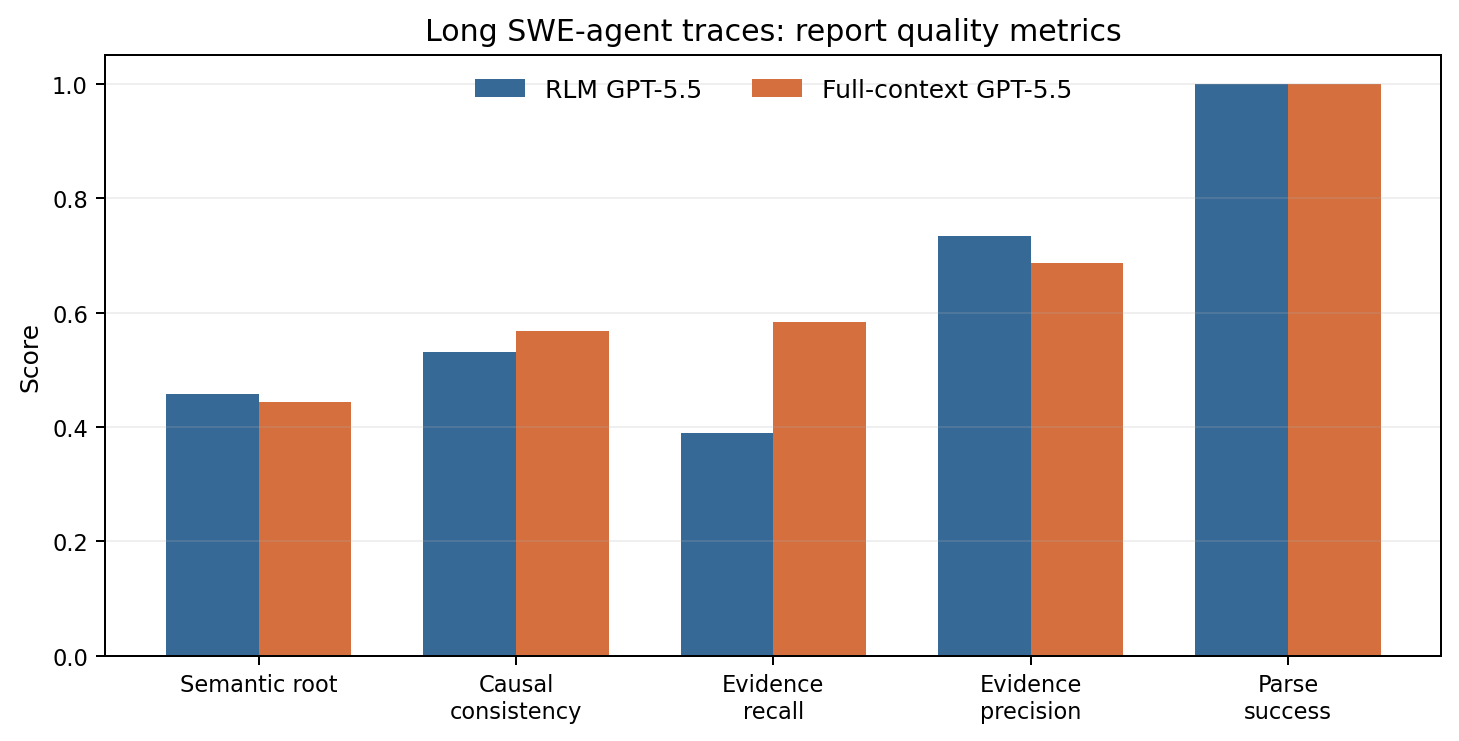
| Metric | RLM GPT-5.5 | Full-context GPT-5.5 |
|---|---|---|
| Semantic root cause | 0.4583 | 0.4440 |
| Causal consistency | 0.5313 | 0.5684 |
| First failure turn error | 0.5556 | 4.0000 |
| Evidence recall | 0.3889 | 0.5833 |
| Evidence precision | 0.7333 | 0.6861 |
| Parse success | 1.0000 | 1.0000 |
At first this looks mixed. RLM is not universally better. Full-context GPT-5.5 has better evidence recall and slightly better causal consistency. But the first-failure result is the important one.
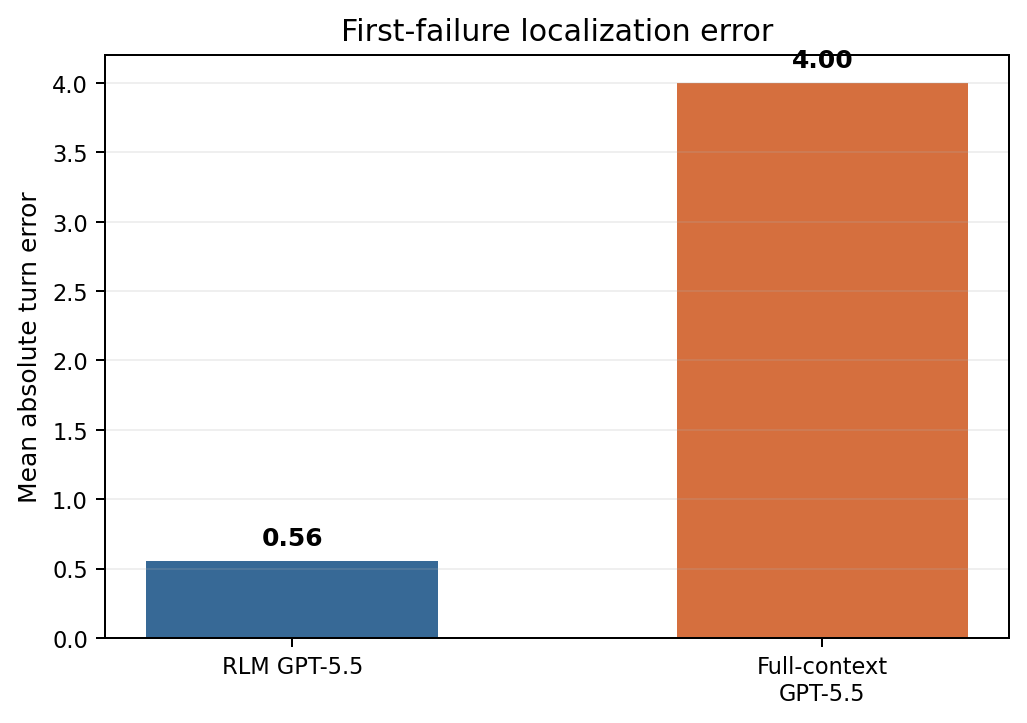
RLM had a mean first-failure turn error of 0.5556. Full-context GPT-5.5 had 4.0000.
That means RLM was much closer to the labeled first causal failure. Full-context GPT-5.5 found more evidence across the trace, but it was less precise about where the causal failure began.
This gave me the first clean long-trace finding:
On real long SWE-agent traces, RLM appears better at localizing the earliest causal failure, while full-context GPT-5.5 is better at broad evidence recall.
That is the result I had been trying to understand. RLM is not magically smarter. Its advantage is structural. Because it breaks the trace into investigated pieces and stores intermediate evidence, it is better suited to asking “where did this start?” Full-context GPT-5.5 is strong at reading the whole trace and collecting many relevant details, but that broad view can blur the earliest causal point.
Case Study: The Invalid Command Loop
One long trace was:
swe-agent-long-01-iterative__dvc-7497
The task was a DVC issue, but the agent almost immediately entered an invalid shell-command loop.
The label was:
| Field | Value |
|---|---|
| Root cause | invalid_mkdir_git_command_loop |
| First causal failure | turn 3 |
| Visible failure | turn 6 |
| Failure type | repeated_invalid_command_loop |
| Trace length | 797 events |
The causal story was:
| Turn | What happened |
|---|---|
| 2 | The user provided the DVC issue. |
| 3 | The agent tried to simulate Git setup instead of investigating the repository. |
| 4 | The shell reported the command was invalid. |
| 6 | The agent repeated the same malformed command. |
| 736+ | The trace was still stuck in the same kind of loop. |
| 797 | The run ended without a real patch. |
RLM’s normalized root cause was:
Severe command perseveration with feedback non-incorporation: the agent repeatedly issued the malformed shell command despite immediate corrective feedback, blocking all task-relevant software engineering work.
This is the simple version:
early bad command -> explicit failure feedback -> same bad command repeated -> no repository work -> timeout
The interesting part is not that the agent failed. That is obvious by the end. The useful part is that RLM marked the first causal failure at turn 3, not near the final timeout.
Case Study: Working in the Wrong Project
Another useful example was:
swe-agent-long-09-iterative__dvc-3534
This one was different. It was not just a malformed command loop. The agent adopted the wrong working premise.
The label was:
| Field | Value |
|---|---|
| Root cause | worked_in_example_project_simulator_instead_of_dvc_source |
| First causal failure | turn 3 |
| Visible failure | turn 13 |
| Failure type | wrong_file_or_location |
| Trace length | 588 events |
The causal story was:
| Turn | What happened |
|---|---|
| 3 | The agent moved away from the actual DVC source context. |
| 5 | It began reproduction work in an example project. |
| 13 | It concluded the real implementation was unavailable. |
| 15 | It created a simulator instead of modifying the actual DVC code. |
| Later | It entered a downstream invalid-command loop and never recovered. |
RLM’s summary was:
The trajectory failed because the assistant abandoned the real DVC repository almost immediately, built and reasoned inside a fake example project, then substituted an unrelated simulator for a production fix.
This case is useful because it separates two layers:
| Layer | Explanation |
|---|---|
| Root failure | The agent worked in the wrong project context. |
| Downstream failure | The agent later got stuck in command repetition. |
That distinction is exactly what failure archaeology is supposed to do. A shallow report might say “the agent looped.” RLM’s better explanation is “the agent first left the real codebase; the later loop made recovery impossible.”
What the Long-Traces Changed
The tau2 result said:
RLM is reliable and auditable, but full-context GPT-5.5 is slightly stronger on short traces.
The SWE-agent result adds:
On long traces, RLM’s structure helps with first-failure localization.
That is a much stronger reason to keep working on this project.
The current picture is:
| Setting | What happened |
|---|---|
| Short tau2 traces | Full-context GPT-5.5 was slightly stronger overall. |
| Long SWE-agent traces | RLM was much better at locating the first causal failure. |
| Evidence behavior | Full-context GPT-5.5 recovered more evidence; RLM cited cleaner evidence. |
| Scientific limitation | The long subset is loop-heavy and LLM-labeled, not human-gold. |
So the more precise thesis is now:
RLM is most useful when the evaluation target is not just “summarize the failure,” but “identify the earliest causal failure in a long trajectory.”
That is the project’s strongest direction.
What I Learned
The short-trace experiment did not show that RLM beats GPT-5.5 full-context. On tau2, full-context GPT-5.5 is still slightly stronger.
But the long-trace experiment made the picture more interesting. RLM can work as an investigation architecture:
- It produces structured reports.
- It stores intermediate reasoning artifacts.
- It can include a no-failure/control hypothesis.
- It can avoid false-positive failures.
- It gives a path for ablations: remove segmentation, remove pruning, remove verification, compare again.
- It can localize early causal failures in long traces more accurately than the full-context baseline in the current SWE-agent slice.
The most useful way to frame the result is:
RLM turns failure analysis from one-shot diagnosis into an auditable investigation process.
That is different from claiming it is always more accurate than full-context GPT-5.5.
My read of the result is:
| Question | Current answer |
|---|---|
| Can RLM produce valid structured reports? | Yes. Parse success was 1.0000. |
| Can RLM avoid false failures on this slice? | Yes. False positive rate was 0.0000. |
| Does RLM beat full-context GPT-5.5 on short traces? | No. Full-context is slightly stronger. |
| Does RLM show an advantage on long traces? | Yes, on first-failure localization in the current SWE-agent slice. |
| Where is RLM weakest? | Evidence recall and causal consistency still need work. |
| Why keep working on RLM? | It gives an auditable structure for long-horizon causal diagnosis. |
What I Would Improve Next
The next improvement should target evidence quality more carefully. On the short tau2 traces, RLM found relevant evidence but was less precise than full-context GPT-5.5. On the long SWE-agent traces, RLM had stronger evidence precision but weaker evidence recall.
So the problem is not simply “cite less evidence” or “cite more evidence.” The better goal is:
cite the smallest set of events that proves the root cause, while preserving enough anchors to explain the trajectory.
The next feature I would add is an event-level entailment checker:
def verify_evidence_item(event, claim):
"""
Return whether this event actually supports the causal claim,
is merely context, contradicts it, or is irrelevant.
"""
...
Then every cited event could be classified before the final report:
| Label | Meaning |
|---|---|
| supports | The event directly supports the claim. |
| context | The event is useful background but not proof. |
| contradicts | The event weakens the claim. |
| irrelevant | The event should be removed. |
That should improve evidence precision and make the causal chains cleaner.
A slightly more complete version would look like this:
def classify_evidence(event, causal_claim):
label = judge_event_relation(event, causal_claim)
if label == "supports":
return {"keep": True, "role": "primary"}
if label == "context":
return {"keep": True, "role": "background"}
if label in {"contradicts", "irrelevant"}:
return {"keep": False, "role": label}
Then the final judge would be allowed to cite only primary evidence for root-cause claims, while background evidence could remain in a separate context field. That should directly target the precision gap.
I would also expand the long-trace benchmark. The current SWE-agent subset is useful, but it is too dominated by command-loop failures. A stronger benchmark should include:
| Needed trace type | Why it matters |
|---|---|
| command loops | tests execution-collapse detection |
| wrong-file edits | tests repository localization |
| incomplete patches | tests task-outcome reasoning |
| test failures | tests evidence from execution output |
| context loss | tests long-horizon memory and instruction retention |
| successful controls | tests false-positive resistance |
Bottom Line
This experiment gave a useful result:
- RLM is reliable on 15 real tau2 traces.
- Full-context GPT-5.5 is still slightly better on short traces.
- On long SWE-agent traces, RLM is better at localizing the first causal failure.
- Full-context GPT-5.5 is still stronger at broad evidence recall on the long slice.
- RLM’s strongest value is auditability plus early-failure localization, not generic benchmark dominance.
- The next bottleneck is evidence quality: knowing which events prove the cause, which are only context, and which are downstream symptoms.
The project is now less of a vague “AI observability” idea and more of a concrete experiment:
Can recursive investigation make agent failure analysis more auditable, more structured, and better at locating the first causal failure in long trajectories?
Supporting Artifacts
The project folder also includes the data-summary and method-diagnostic figures that supported the report:
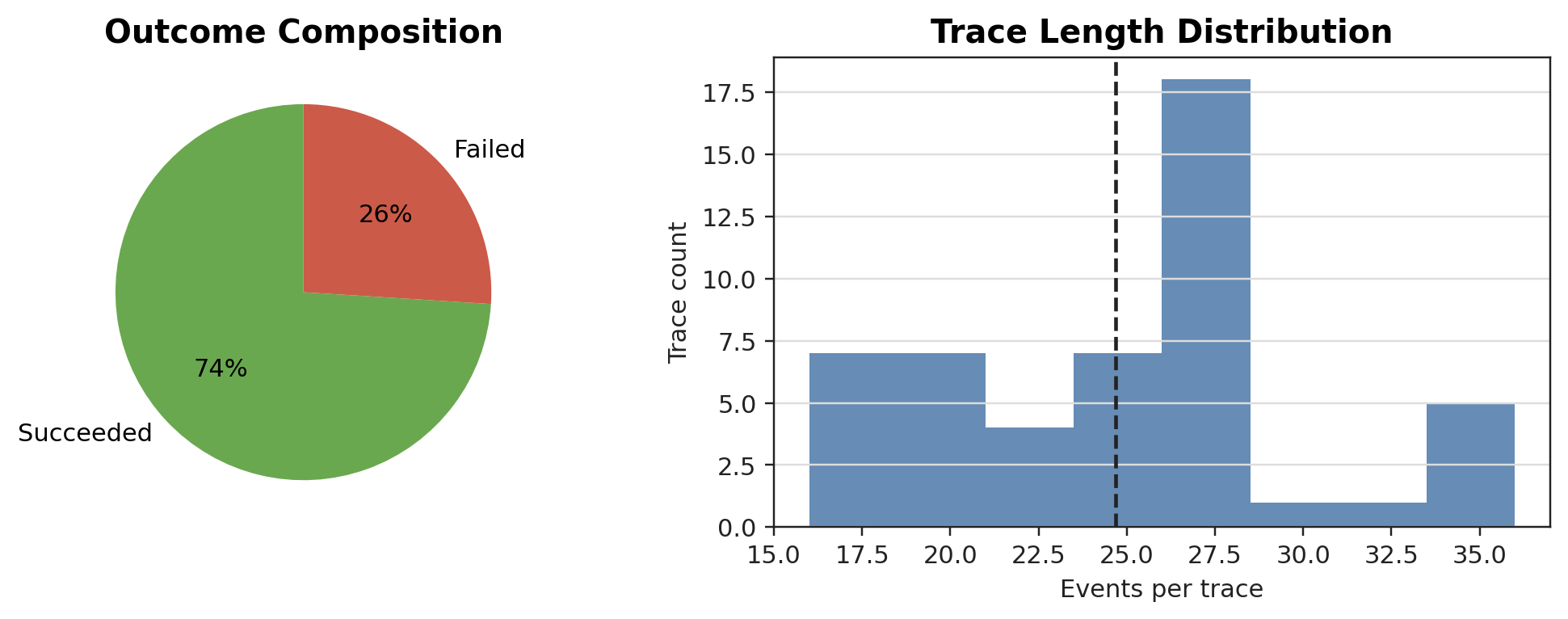
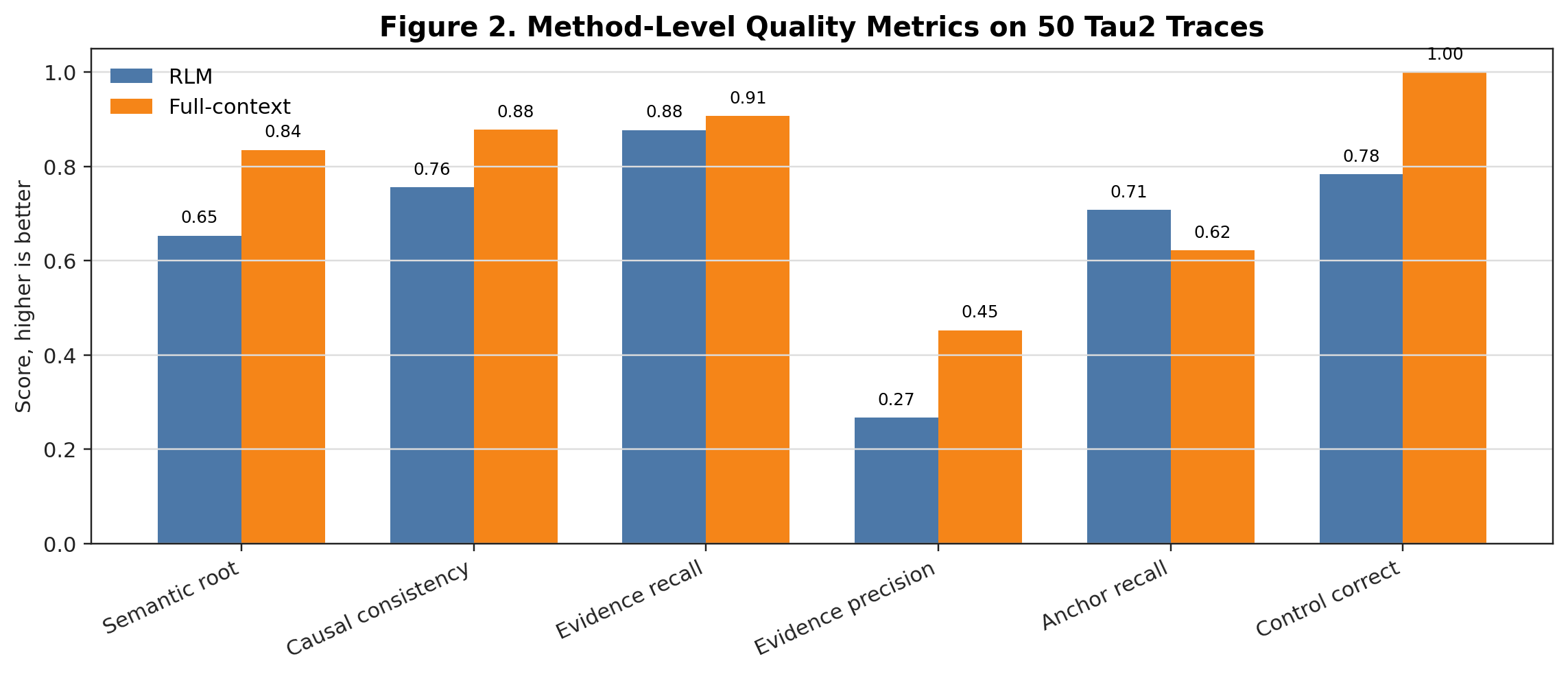
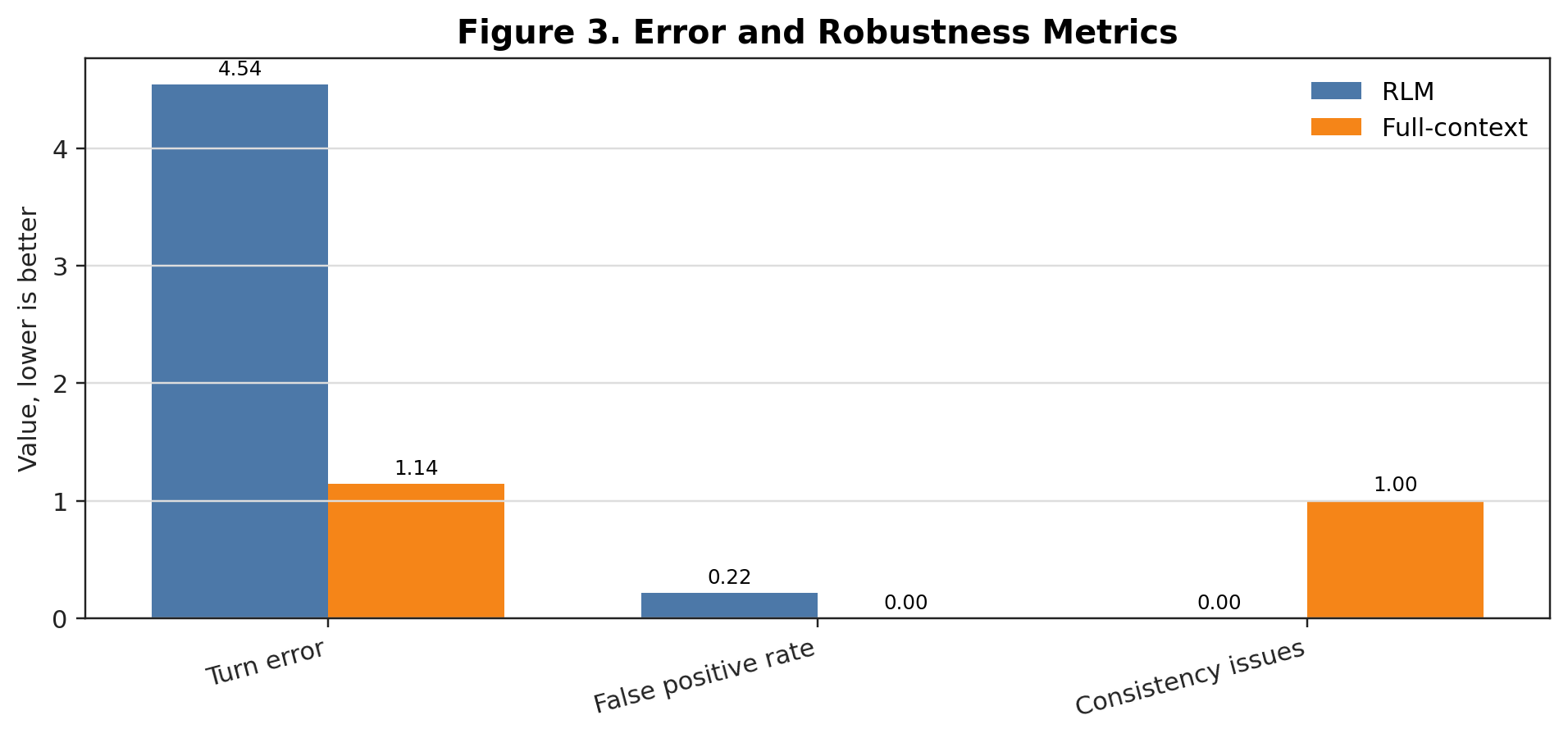
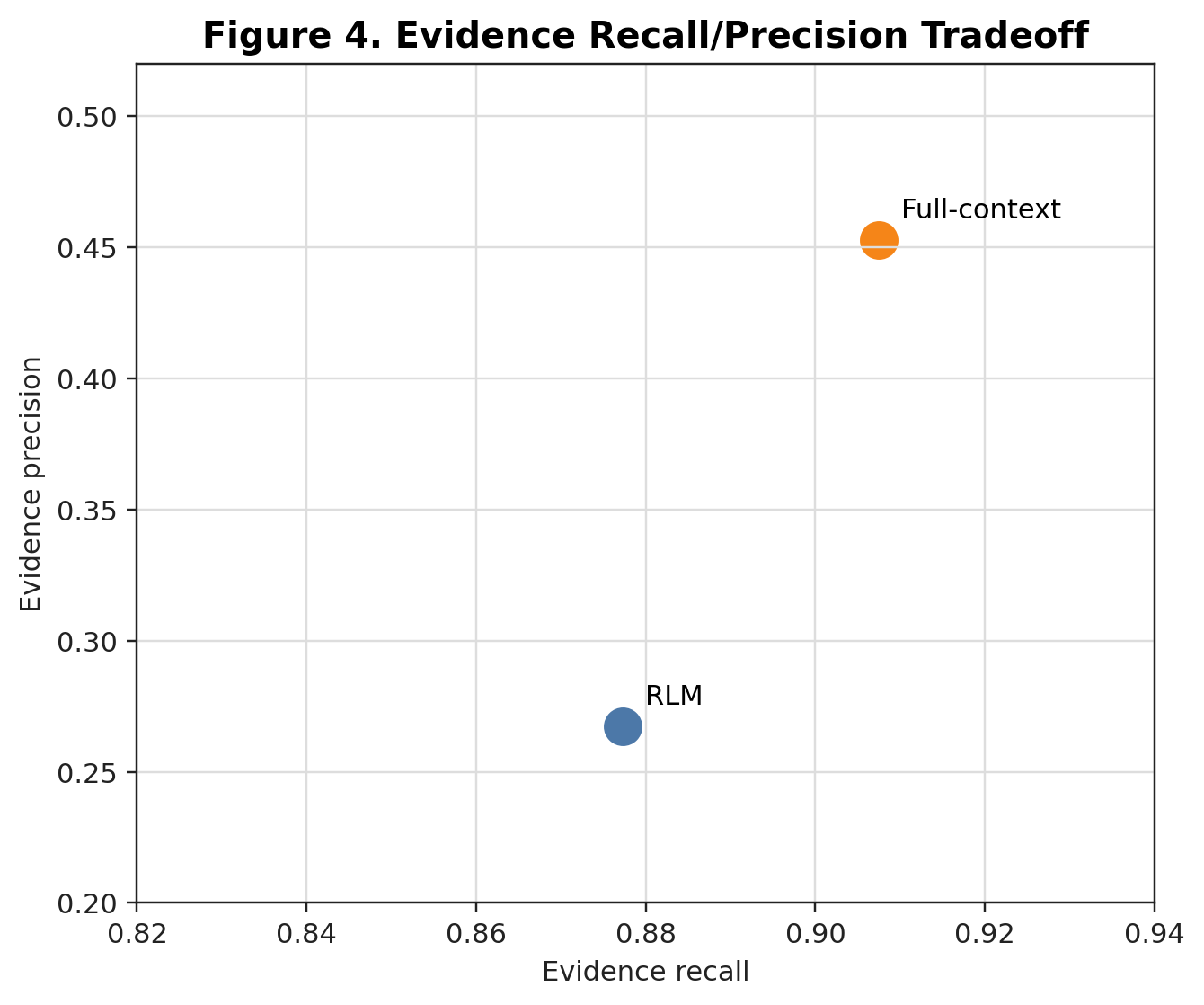
Supporting tables and reproduction script: