AlphaGo, Search, and Automated AI Research
My notes from Dwarkesh Patel and Eric Jang on rebuilding AlphaGo, MCTS labeling, Tree of Thoughts, RL, off policy learning, test time scaling, and automated AI research.
AlphaGo, Search, and Automated AI Research
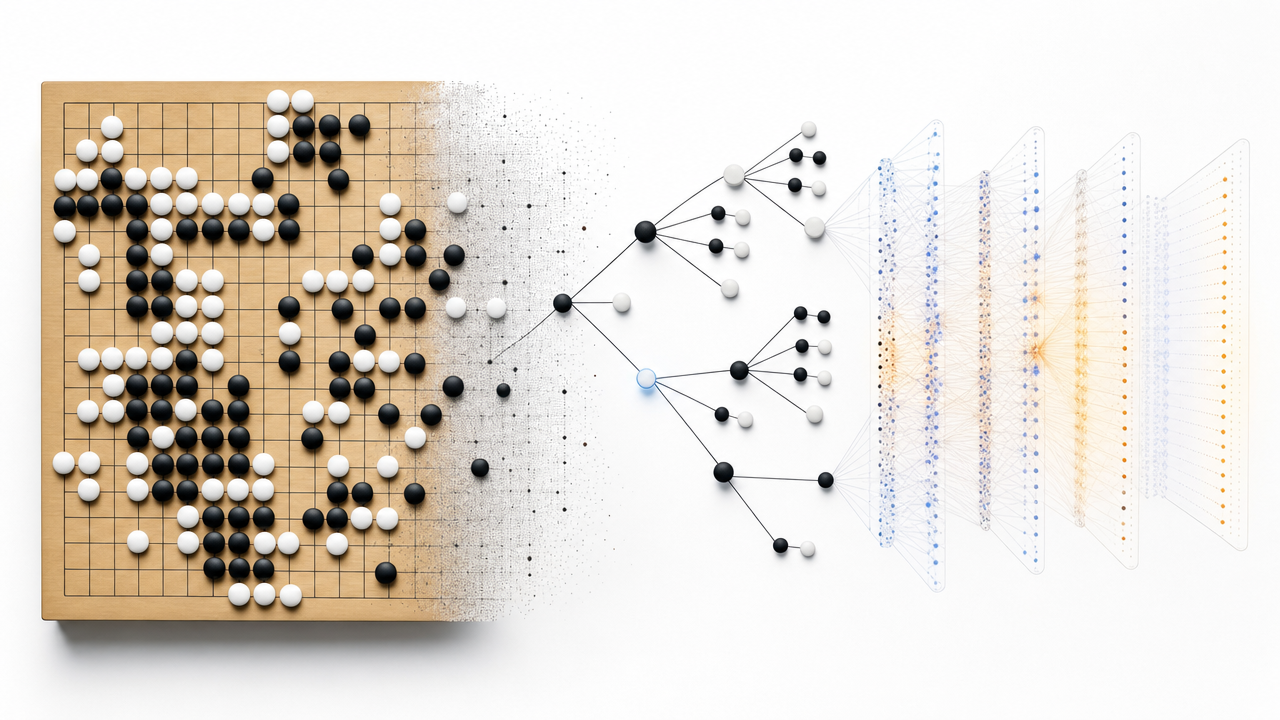
I watched the Dwarkesh Patel conversation with Eric Jang about rebuilding AlphaGo from scratch, and the thing that stayed with me was not only that AlphaGo is still beautiful. It was that AlphaGo gives a very concrete mental model for many questions that now feel central to language models, agents, robotics, and automated AI research.
The episode starts as a tutorial on Go and Monte Carlo Tree Search, but it slowly turns into something broader. It becomes a discussion about how to get better labels, why search can act like a teacher, why reinforcement learning can be brutally sample inefficient, why initialization matters, why off policy data is both useful and dangerous, and why current AI research agents can grind experiments but still struggle to step back and reason from first principles.
The video is here: Dwarkesh Patel with Eric Jang.
I also reread the NeurIPS 2023 paper Tree of Thoughts: Deliberate Problem Solving with Large Language Models, because Eric mentions that Google had research around tree structures for reasoning in 2023 or 2024. Tree of Thoughts is not AlphaGo for language, but it is one of the clearest attempts to ask the same question in a language setting: can a model explore multiple possible intermediate states, evaluate them, prune bad paths, and backtrack instead of committing to one left to right sample?
This post is my attempt to connect those pieces.
The post is not a transcript summary. It is more like a map of the ideas that I think matter after listening to the episode and reading the paper. The interesting theme is that many systems we call reinforcement learning are really trying to solve a labeling problem. The agent acts in the world, but the hard part is not only exploration. The hard part is discovering which local decisions should receive credit, which decisions should be corrected, and how to turn sparse outcomes into training targets that do not destroy the model with variance.
That framing makes AlphaGo feel less like an isolated historical result and more like a template. Search gives better local labels. The neural network absorbs those labels. The improved neural network makes future search cheaper and stronger. In language models, we are still searching for an equivalent loop. Current RL for LLMs often waits for the whole answer to succeed or fail. Tree of Thoughts tries to make reasoning less like one long sample and more like a deliberate search process. Automated research agents try to do something similar at the level of experiments, where the nodes are hypotheses, the branches are runs, and the value function is some mixture of benchmark score, experiment taste, and judgment about what is actually worth pursuing.
That is why the conversation felt important to me. It gives one clean solved case, Go, and several messy open cases, language reasoning, robotics, and AI research itself. The clean case does not directly solve the messy ones, but it gives a vocabulary for talking about them.
The core AlphaGo idea is not just RL
When people say AlphaGo is a reinforcement learning system, that is true, but it can hide the most important part. The elegant part is that AlphaGo converts search into supervised learning targets.
In a naive policy gradient setup, an agent plays a full game, receives a win or loss at the end, and then tries to increase the probability of the actions that happened in winning trajectories. That is a very weak signal. A game can have hundreds of moves, and maybe only one of those moves was the reason the game was won. If the algorithm upweights the whole trajectory, most of the update is noise.
MCTS does something different. For every state the agent actually reaches, it asks a stronger local question:
Given this state, if I search forward using my current policy and value function, what distribution over actions looks better than my first guess?
That gives a target for every visited state. Not just the final winner. Not just the whole trajectory. Every move gets relabeled with an improved action distribution.
This is why Eric frames AlphaGo as much closer to stable supervised learning than people sometimes realize. The network is trained to predict:
\[\pi_{\theta}(a \mid s) \approx \pi_{\text{MCTS}}(a \mid s)\]and
\[v_{\theta}(s) \approx z\]where (z) is the final game outcome from that state perspective.
The policy target is not just the single move that MCTS selected. It is the visit count distribution produced by search. That matters because a distribution carries more information than a one hot label. In information terms, a soft target can have much higher entropy:
\[H(p)=\sum_i p_i \log \frac{1}{p_i}\]That is one of the underrated lessons. AlphaGo is not merely learning from wins. It is distilling a search procedure into a neural network. The search improves the label. The network amortizes the search. Then the next search starts from a better network.
The loop is:
-
Start with a policy and value network.
-
Use MCTS to improve the policy at a state.
-
Play using the improved search policy.
-
Store the state, the search distribution, and the eventual outcome.
-
Train the network to predict those improved labels.
-
Repeat.
That loop is why MCTS labeling feels like an alternative to naive RL. It turns an outcome signal into dense local targets.
This is the part that changes how I think about the phrase reinforcement learning. The word reward makes it sound like the system is mostly learning from a final scalar. But AlphaGo’s practical strength comes from building a better supervised learning dataset out of search. The reward still matters. The final game result trains the value head. But the policy head is not just told that the winning player’s moves were good. It is told what search believed after looking ahead from each state.
That difference matters because the naive trajectory level signal has a credit assignment problem. Imagine a game with 300 moves. If the black player wins, we could upweight all black moves. But maybe 280 of those moves were obvious, 19 were neutral, and one move was genuinely brilliant. The final win does not tell us which is which. MCTS creates a more local training signal. At move 87, it searches from the actual board and returns a new distribution. At move 122, it does the same. Each state gets its own correction.
In that sense, the search policy is a teacher. It is not a perfect teacher, because it depends on the value function and the number of simulations. But it is a teacher that can produce a label for every state the learner actually visits. That is the bridge to imitation learning and DAGGER. You let the learner visit its own states, then you ask a stronger policy what the learner should have done there.
The beautiful part is that the student eventually makes the teacher cheaper. Early on, MCTS may need many simulations to turn a weak policy prior into a useful distribution. Later, after training on many MCTS targets, the raw policy already resembles the search output. That means the next round of search begins from a stronger prior and can spend its compute on harder distinctions. Expensive deliberation becomes cheap intuition.
That is also one way to understand test time scaling. The model can spend compute at inference time to search, but training can distill some of that search into the weights. The frontier between explicit reasoning and amortized reasoning moves as the model improves.
How MCTS labeling works
The most useful way to think about MCTS labeling is as a local improvement operator.
Suppose the policy network sees a Go board and assigns a probability distribution over legal moves. On a 19 by 19 board, that can be up to 361 moves. The raw network might already be strong, especially if it was initialized from expert games, but it is still a fast intuition. MCTS takes that intuition and asks: if I spend compute searching from here, does the distribution become sharper and better?
At the end of the search, the visit counts become the new label:
\[\pi_{\text{MCTS}}(a \mid s)=\frac{N(s,a)^{1/\tau}}{\sum_b N(s,b)^{1/\tau}}\]Here (N(s,a)) is the number of times search selected action (a) from state (s), and (\tau) controls how sharp the distribution becomes.
This is not simply choosing the argmax move. The full distribution says something like: this move is best, these two are plausible, those twenty are bad, and the rest are almost never worth visiting. That is a richer label than a single answer.
Eric connects this to DAGGER style imitation learning. In DAGGER, a learner visits states under its own policy, then an expert corrects the action at those states. The important thing is that the expert labels the states the learner actually visits, not only ideal states from a perfect demonstration distribution.
MCTS plays the expert role. Even if the game trajectory eventually loses, search can still say, at this state, a better local action would have been this distribution. That is powerful because the learner gets correction signal even in imperfect trajectories.
The guarantee is not absolute. If the value function is wrong, search can become wrong. If the number of simulations is too low, search can have high variance. If late game value estimates are bad, bad values can back up through the tree. But when the value function is grounded, search is usually a better teacher than the raw policy.
That is the deep reason initialization matters. You do not want to spend expensive search compute on garbage values. Eric’s practical advice is very sane: start from something that works. Use expert games. Use a strong open source Go bot. Use small boards. Get the rules and value head working before trying to learn everything from nothing.
In his phrasing, initialization is everything. Always start from something close to success, then make it better, rather than starting from a system that does not work and hoping learning will rescue it.
I think this advice is easy to underestimate because it sounds almost too practical. But it is a deep research principle. A lot of failed RL work begins with a flat reward surface. The agent does not solve the task, so it gets no positive signal, so it cannot learn to solve the task. In language models, this is the same shape as asking a weak model to solve a hard programming task by random exploration. If it almost never passes the tests, most samples teach almost nothing.
AlphaGo avoids the worst version of that trap by arranging the problem so that there is always a local improvement target. But even there, Eric emphasizes that the value function has to be grounded. If the value head is nonsense, search over nonsense can produce a worse policy target than the original policy. That is why expert games, open source Go bots, or small board pretraining are not philosophical compromises. They are ways of getting the system into the regime where the improvement operator is actually helpful.
This maps directly to my own experience with post training and agent training. The first goal is not to be maximally pure. The first goal is to get into a nonzero signal regime. Once the system can do something, even imperfectly, you can evaluate, relabel, refine, and scale. Before that, you are often just staring at noise.
There is also a subtle point about value and policy sharing representations. AlphaGo Lee used separate networks. Later versions moved toward a shared trunk with two heads. That makes intuitive sense because the policy and value should not be independent. If the policy says a move is excellent but the value head says the resulting state is terrible, something is inconsistent. Search exposes that inconsistency. Training pushes the two heads toward a shared representation of what matters on the board.
UCB and PUCT are ways of spending attention
The search problem in Go has two sides: breadth and depth.
Breadth is the number of possible actions. Depth is how far into the future you need to reason before the value of an action becomes clear. AlphaGo shrinks both. The policy network shrinks breadth by proposing promising actions. The value network shrinks depth by estimating who is likely to win without playing the whole game to the end.
Before AlphaGo, Monte Carlo search already needed a rule for deciding which branch to explore. The classic intuition comes from UCB, or upper confidence bound methods. A simple version looks like:
\[\operatorname{UCB}(a)=Q(a)+c\sqrt{\frac{\ln N}{1+N(a)}}\]The first term is exploitation. It says: choose actions with high estimated value.
The second term is exploration. It says: if an action has not been tried much, give it a bonus.
PUCT modifies this idea by using the policy network prior:
\[\operatorname{PUCT}(s,a)=Q(s,a)+c_{\text{puct}}P(s,a)\frac{\sqrt{N(s)}}{1+N(s,a)}\]That (P(s,a)) term is important. It is the neural network saying, before search, this action looks plausible. So PUCT does not explore uniformly. It explores in a policy guided way. The neural network tells search where to look first, and search corrects the neural network when deeper evaluation disagrees.
This is also where the notion of probability enters a deterministic game.
Go itself is deterministic. If we had infinite compute, there would be no need to talk about probabilities. From a given state, perfect play has a definite answer. But we do not search the whole tree. We sample a tiny part of it. The probabilities come from the search process and the policy prior. They describe uncertainty over which parts of the tree we will explore and which actions are promising under limited compute.
So probability in AlphaGo is not randomness in the game. It is randomness and uncertainty in the computation we can afford.
That distinction is useful outside Go too. Many AI systems are deterministic once you fix the model weights, prompt, sampling seed, and environment. But the training process still uses probability because the system cannot evaluate every possible continuation. It samples. It estimates. It allocates compute. In that sense, probability is often not a property of the world. It is a property of bounded reasoning.
UCB and PUCT are compute allocation rules. They answer the question: where should I spend my next simulation? A bad rule wastes search on hopeless branches. A good rule keeps enough exploration to avoid missing surprises while still concentrating on high value regions.
PUCT is especially interesting because it mixes learned intuition with explicit uncertainty. The policy prior (P(s,a)) is the network’s instinct. The visit count (N(s,a)) is the search process remembering what it has already investigated. The value (Q(s,a)) is the current estimate from simulation. None of these alone is enough. The prior can be wrong. The value can be noisy. The count bonus can overexplore. Together, they form a practical balance.
This is one of the reasons I do not think of MCTS as brute force. It is not enumerating the tree. It is an attention mechanism over possible futures. The policy prior tells it where to look. The value head tells it when it can stop. The count bonus keeps it from becoming too greedy too early.
The four step MCTS process
Eric breaks MCTS into four steps:
-
Selection.
-
Expansion.
-
Evaluation.
-
Backup.
Selection walks down the current tree using PUCT. It chooses the child that looks best under the sum of value and exploration bonus.
Expansion happens when search reaches a state that is not yet in the tree. The system adds children for legal actions, often initialized with policy priors from the network.
Evaluation uses the value network to estimate the state. In original AlphaGo Lee, this could be mixed with a rollout to the end of the game. Later systems usually relied more directly on the value network.
Backup propagates the evaluated value back up the path. Each visited edge updates its count and mean value.
Mathematically, if a simulation returns value (v), the running action value can be updated as:
\[Q_{\text{new}}(s,a)=\frac{N(s,a)Q(s,a)+v}{N(s,a)+1}\]After enough simulations, the visit counts become the search policy. That is the label the neural network learns to imitate.
The important conceptual point is that the tree is built while it is searched. Go is too large for an exhaustive tree. MCTS only expands the parts that look worth expanding.
Selection is where the algorithm decides which already known path deserves another look. It starts at the root, evaluates each child with the PUCT score, chooses the best child, then repeats until it reaches a leaf or an expandable state.
Expansion is where the tree grows. The algorithm takes a state that has not been fully explored and adds children for possible legal moves. In AlphaGo style systems, these children are initialized with priors from the policy network. So the tree is not born blank. It is born with a learned guess about which moves are worth considering.
Evaluation is where the value network replaces a full rollout. In early AlphaGo, the system partly grounded evaluation with actual playouts. Later systems leaned more heavily on the learned value function. This is a major compute saving because a value function can summarize the expected outcome of a position without rolling the game to completion.
Backup is the part that makes search cumulative. The evaluated value is pushed back up along the path. Counts increase. Mean values update. Future selections are changed by this new information.
If you stare at this loop long enough, it starts to look like a micro version of research. Select a promising direction. Expand it into concrete experiments. Evaluate the result. Back up what you learned into your beliefs. Repeat. That analogy is imperfect, but it explains why this episode naturally ends up talking about automated research. Search, learning, and research are all versions of the same loop when they are formalized enough.
Neural networks make search tractable
The neural network has two heads.
The policy head predicts a distribution over moves:
\[\pi_{\theta}(a \mid s)\]The value head predicts the probability of winning:
\[v_{\theta}(s)\]The policy head answers: where should I look?
The value head answers: how good is this state?
Together, they compress an enormous amount of possible future simulation into a fast forward pass. This is the part Eric finds profound. A relatively small neural network can amortize a search problem that looks intractable if you insist on exact enumeration.
That does not mean the network solves Go in the formal worst case sense. It means real Go positions have structure. The network learns macroscopic patterns that correlate with victory. It does not need to predict the exact future board hundreds of moves later. It needs to predict a coarser quantity: who is likely to win.
This connects to a bigger theme in AI. Many hard problems are hard in the worst case, but real distributions contain structure. Protein folding, board games, robotics, and language all contain patterns that networks can exploit. AlphaGo was one of the first systems that made that feel concrete.
Test time scaling and reasoning
One of the most interesting parts of the conversation is the connection between MCTS and test time scaling.
If you run more simulations per move, the Go bot usually gets stronger. That is test time compute. But if you train the neural network to imitate the result of search, some of that test time compute gets packed into the model. The next time you run search, it starts from a stronger prior.
That creates a tradeoff between training compute and inference compute. You can spend more compute during search, or you can train the network so that less search is needed.
This is directly relevant to language models. Modern reasoning models also spend more compute at inference time. They generate longer thoughts, check intermediate work, sample alternatives, or use tools. The open question is how much of that explicit reasoning can be distilled back into the base model.
AlphaGo gives one clean answer in a clean domain: search can produce better labels, and the network can absorb those labels.
For LLMs, the domain is much messier. Language actions are too broad, values are harder to define, and the same child is rarely sampled twice. Still, the shape of the idea is deeply relevant.
Why LLM RL often treats a whole answer as one action
Eric makes a useful point about why current LLM RL often treats an entire sampled completion as one action rather than a long multi step action sequence.
A completion is made of tokens, but the reward is often given only at the end. The code passed tests or it did not. The math answer was correct or it was not. The user preferred one response or another.
If you try to assign credit token by token, variance can explode. Which token mattered? Which intermediate sentence was responsible for success? Which part was neutral? Which part was harmful?
For an autoregressive model:
\[\log p_{\theta}(y \mid x)=\sum_t \log p_{\theta}(y_t \mid x,y_{1:t})\]But the reward may apply to the whole sequence:
\[R(y)\]The basic policy gradient signal has to multiply the sequence log probability by that sequence reward. If the sequence is long and most tokens are irrelevant to success, the learning signal becomes noisy.
That is why advantage estimation matters. In RL, the goal is not merely to reward winning actions. It is to reward actions that did better than expected from that state. You need a baseline, a value estimate, or a critic. Without that, you do not know whether a winning trajectory won because of a specific action or despite it.
This is where Dwarkesh’s comparison between supervised learning and RL is sharp. With supervised learning, if the correct next token is blue and your model assigns it tiny probability, the cross entropy label tells you exactly how far off you are. You get dense information immediately:
\[\text{bits from label}=\log_2 \frac{1}{p(\text{correct})}\]With RL, if the model guesses wrong, it mostly learns that this sampled attempt failed. If the action space is huge, most samples are failures. You can spend a long time getting almost no useful signal.
That is why initialization matters again. If your pass rate is zero, RL may never find the first success. AlphaGo avoids much of this because MCTS can improve the local policy before the agent has to solve the entire game by luck.
Why language trees are harder than Go trees
Eric’s example of where LLMs break down is simple and important.
In Go, PUCT can revisit the same child many times. A legal move is a stable discrete object. Search can say: I have visited this move 50 times and that move 2 times.
In language, the action space is enormous. If a thought is a paragraph, the odds of sampling the exact same child twice are tiny. Even if thoughts are token sequences, the meaningful unit is not always a token. It might be a plan, a theorem step, a tool call, or a subgoal.
That means the PUCT style count bonus is not obviously the right heuristic. The expression
\[\frac{\sqrt{N(s)}}{1+N(s,a)}\]assumes repeated visits to the same child are meaningful. In language, two children can be semantically similar but syntactically different. Counting exact children can miss the real structure.
This is why applying tree search to LLM reasoning is difficult. The breadth is too large, the value function is weaker, and the units of action are not naturally defined.
Still, the Tree of Thoughts paper is valuable because it tries to move the unit of search from tokens to thoughts.

Tree of Thoughts frames problem solving as a search over coherent language states:
\[s=[x,z_{1:i}]\]Here (x) is the original problem, and (z_{1:i}) are the thoughts so far.
The method asks four questions:
-
What counts as a thought?
-
How do we generate candidate thoughts?
-
How do we evaluate partial states?
-
What search algorithm do we use?
The paper uses breadth first search for Game of 24 and creative writing, and depth first search with backtracking for crosswords. The reported Game of 24 result is striking: GPT 4 with chain of thought solved 4 percent, while Tree of Thoughts reached 74 percent.
That does not mean ToT solves reasoning. It means there are tasks where explicitly maintaining alternatives, evaluating partial progress, and backtracking can unlock capabilities that single path chain of thought misses.
The relationship to AlphaGo is not identity. AlphaGo has a clean simulator and a grounded value function. ToT has language based self evaluation. But the philosophical connection is real: reasoning improves when the model can explore a tree rather than commit to one sample.
A closer breakdown of Tree of Thoughts
The Tree of Thoughts paper starts from a simple criticism of normal language model inference. A language model generates tokens left to right. Once it chooses a token, the next token is conditioned on that choice. This is powerful, but it creates a commitment problem. If the model makes a bad early decision, the rest of the completion may be trapped by that decision.
Chain of thought prompting improves this by making the model produce intermediate reasoning. But ordinary chain of thought still usually follows one path. The model writes a reasoning chain, then an answer. Self consistency improves this by sampling many independent chains and choosing the most common answer. But even self consistency does not do local search inside a reasoning path. It samples separate full trajectories.
Tree of Thoughts changes the unit of reasoning. Instead of treating each token as the only decision point, it treats a thought as a coherent intermediate step. A thought could be a line of arithmetic in Game of 24, a paragraph level writing plan in creative writing, or a proposed word in a crossword. This matters because tokens are usually too small to evaluate, while a full answer is often too large to correct. A thought sits in the middle. It is big enough to judge and small enough to branch.
Formally, the paper defines a state as:
\[s=[x,z_{1:i}]\]where (x) is the problem input and (z_{1:i}) is the sequence of thoughts chosen so far. A candidate next thought extends the state:
\[s'=[x,z_{1:i},z_{i+1}]\]The method then needs four components.
First, it needs a thought decomposition. This is domain dependent. In Game of 24, a thought is one arithmetic operation that combines two numbers and leaves a smaller set of numbers. In creative writing, a thought can be a plan. In crosswords, a thought can be a proposed clue fill. This is not a minor implementation detail. The choice of thought unit determines whether search is useful. If the unit is too small, evaluation becomes meaningless. If the unit is too large, branching becomes too expensive.
Second, it needs a thought generator. The paper describes two modes. One mode samples independent thoughts from a normal chain of thought style prompt. This works when the space is rich and diversity is natural, such as writing plans. Another mode proposes several thoughts sequentially in the same prompt. This is useful when the space is constrained, because it reduces duplicate proposals. In Game of 24, for example, the model can propose multiple arithmetic next steps from the same current state.
Third, it needs a state evaluator. This is the paper’s substitute for a learned value function. Instead of training a neural value model like AlphaGo, Tree of Thoughts asks the language model itself to evaluate the promise of partial states. There are two main styles. One is value evaluation, where the model independently scores a state as promising or not. The other is voting, where the model compares several states and chooses the best one.
Fourth, it needs a search algorithm. The paper uses breadth first search and depth first search. Breadth first search keeps a frontier of promising states at each step. Depth first search explores a promising path until it succeeds or the evaluator says the path is unlikely, then it backtracks.
This is the conceptual algorithm:
\[S'_t=\{[s,z] : s\in S_{t-1}, z\in G(p_{\theta},s,k)\}\]The candidate states (S’_t) are evaluated:
\[V_t(s)=V(p_{\theta},s)\]Then the search keeps only a subset of promising states:
\[S_t=\operatorname{TopB}_{s\in S'_t} V_t(s)\]That is the core of Tree of Thoughts. Generate possible thoughts, evaluate partial states, keep the best frontier, and continue.
The Tree of Thoughts tasks
The most famous result in the paper is Game of 24. The input is four numbers, and the model must use each number exactly once to make 24. A normal chain of thought can easily make an early arithmetic decision that looks plausible but destroys the path to 24. Tree of Thoughts decomposes the problem into three arithmetic steps. At each step, the model proposes possible operations, evaluates whether the remaining numbers can still reach 24, and keeps promising candidates.
The paper reports that GPT 4 with chain of thought solved 4 percent of the Game of 24 tasks, while Tree of Thoughts solved 74 percent. That result is striking because it is not about adding new model weights. It is about changing inference from one path generation into search.
The second task is creative writing. Here, the problem is not a crisp mathematical target. The model receives random sentences and must write a coherent passage ending in those sentences. For this domain, the paper uses voting more than scalar value. The model generates several plans, compares them, chooses a strong plan, then writes and evaluates outputs. This shows that Tree of Thoughts is not only for arithmetic. It can also act as structured deliberation in open ended tasks.
The third task is mini crosswords. This is closer to a classical search problem. The model proposes words for clues, fills partial grids, evaluates whether constraints remain feasible, and backtracks when a path becomes impossible. This is where the paper’s DFS framing matters. Backtracking is not an optional feature here. Without it, the model can fill itself into a corner.
These tasks were chosen because ordinary left to right generation is weak on them. They require planning, lookahead, and correction. That is exactly the failure mode Tree of Thoughts targets.
How Tree of Thoughts relates to AlphaGo
The AlphaGo connection is not that Tree of Thoughts is doing AlphaGo style MCTS. It is not. The paper mostly uses BFS and DFS. It does not have a perfect simulator, a trained value network, or repeated visits to the same stable action child in the way Go does.
The connection is more abstract.
AlphaGo says: do not trust the raw policy alone. Generate alternatives through search, evaluate them, and train or act using the improved result.
Tree of Thoughts says: do not trust one chain of thought alone. Generate alternative thoughts, evaluate partial reasoning states, and choose a path using search.
In AlphaGo, the value function is learned from games and grounded by win loss outcomes. In Tree of Thoughts, the evaluator is usually the language model itself. That is much weaker, but also more general. You can apply it without training a domain specific value network.
In AlphaGo, the action space is legal moves on a board. In Tree of Thoughts, the action space is language thoughts. That is much harder because thoughts are not naturally discrete in the same clean way. Two different strings can represent the same plan. One thought can contain several hidden decisions. Evaluation can be biased by phrasing.
In AlphaGo, the environment transition is exact. If you place a stone, the next board is determined. In Tree of Thoughts, the transition from one thought to the next is semantic. The model is not updating a formal world state unless the task has one, like Game of 24 or crosswords.
So the correlation is real but limited. Tree of Thoughts borrows the search mindset, not the full AlphaGo machinery.
The strongest version of the comparison is this:
\[\text{AlphaGo}=\text{policy prior}+\text{value function}+\text{tree search}+\text{distillation}\]while:
\[\text{Tree of Thoughts}=\text{thought generator}+\text{LM evaluator}+\text{tree search}\]The missing piece in Tree of Thoughts is distillation. The paper improves inference, but it does not train the model to internalize the improved search traces. That is where future work becomes interesting. If a model repeatedly solves problems through thought search, can we train it to predict the successful search distribution directly? Can we distill tree search into a stronger reasoning policy? That would be much closer to the AlphaGo loop.
What the paper gets right and where it is limited
What Tree of Thoughts gets right is the unit of search. It recognizes that token level branching is usually the wrong abstraction. The meaningful unit is a thought. This is similar to how a human does not usually reason by considering every possible next word. A human considers approaches, partial plans, equations, proof moves, hypotheses, or subgoals.
It also gets modularity right. The generator, evaluator, and search algorithm are separate. You can change how thoughts are proposed, how states are scored, and how the tree is traversed. That makes the method more like a framework than a single prompt trick.
But the limitations are important.
The evaluator can be wrong. A language model judging its own partial reasoning can be overconfident, style biased, or fooled by fluent nonsense. In Go, the value function is grounded by game outcomes. In Tree of Thoughts, the value function is often just another prompt.
The search can be expensive. Sampling multiple thoughts, evaluating each one several times, and searching a tree can consume many more tokens than a single chain of thought. The paper acknowledges cost. This means Tree of Thoughts is most useful when the task is hard enough that extra inference compute is justified.
The thought decomposition is hand designed. The paper does not solve the general problem of discovering the right reasoning unit. A good thought unit for Game of 24 is obvious. A good thought unit for research, negotiation, or long horizon software engineering is much less obvious.
The method does not automatically learn from its own search. It can solve a problem better at inference time, but unless we store and train on the traces, the base model does not necessarily improve.
These limitations do not make the paper weak. They define the next research program. The paper is valuable because it makes the search abstraction explicit, shows that it can work on tasks where chain of thought fails, and gives a concrete bridge between LLM reasoning and older search based AI.
Why the Tree of Thoughts result matters for reasoning models
The reason I care about Tree of Thoughts is not only the Game of 24 number. It is that the paper separates reasoning into three objects: generation, evaluation, and search.
Most prompting discourse collapses these together. We ask the model to think step by step, and the same sample contains the plan, the reasoning, the evaluation, and the answer. Tree of Thoughts makes those roles separable. The model can generate candidate thoughts. The model can judge candidate thoughts. A search algorithm can decide which candidates survive.
That separation feels important for agents. In an agent system, generation might be proposing tool calls. Evaluation might be a verifier, a unit test, a reward model, a simulator, or another model. Search might be BFS, DFS, beam search, MCTS, or something more domain specific. Once those pieces are separated, we can improve each one.
This is also why the paper correlates with Eric’s point about forward search. In Go, forward search is powerful because it can locally improve the next move. In language, we need domains where partial states are evaluable. Tree of Thoughts shows that some domains have enough structure for this to help. The challenge is extending that to richer tasks without making the search space explode.
NFSP, best response policies, AlphaStar, and OpenAI Dota
The conversation then moves to cases where you cannot easily do MCTS.
Go is perfect information and deterministic. StarCraft, Dota, robotics, and many real environments are not like that. The state is partially observed. The action space can be continuous or huge. The simulator may not be available as a clean searchable tree.
So how do you get better labels when search is not easy?
Eric points to neural fictitious self play and best response training. The idea is to fix an opponent policy, then train a best response policy against it using model free RL. If that best response becomes strong, it can provide labels for how to act against that opponent. Across many opponents, you can distill a mixed strategy.
This is related to systems like AlphaStar and OpenAI Five for Dota. They could not simply run AlphaGo style tree search over the full game. Instead, they trained policies through large scale self play, league training, best responses, and model free RL methods.
The common theme is still relabeling behavior with something better. In AlphaGo, the better teacher is MCTS. In NFSP style systems, the better teacher can be a best response policy trained against a fixed opponent.
The details differ, but the direction is similar:
-
Generate behavior.
-
Find a stronger behavior signal.
-
Distill that signal into a policy.
-
Repeat against a changing population.
This is one of the main bridges between board game search and modern agent training.
NFSP is worth spelling out because it gives a different answer to the same question MCTS answers in Go. The question is: where do better labels come from?
In Go, better labels come from search. The agent can simulate the future using exact rules, ask the value function to evaluate leaves, and back up values. In StarCraft or Dota, the full future is much harder to search. The state is partially observed. The number of possible actions is huge. The environment has timing, hidden information, and multi agent dynamics. A direct Go style tree is not practical.
So a best response policy becomes a substitute teacher. You fix an opponent or a population of opponents, then train a policy to beat that opponent. Once the best response is strong, it contains information about what actions are effective against that opponent. You can distill those actions back into a broader policy.
This creates a league dynamic. A policy learns to beat one opponent, then another, then another. If done well, the final policy does not merely overfit to one opponent. It becomes a mixed strategy that performs well across a distribution of opponents.
That is why AlphaStar and OpenAI Five are relevant. They show that when explicit tree search is not available, you can still create improvement pressure through self play, opponent populations, best response training, and distillation. The improvement operator is no longer MCTS. It is a training system that produces stronger policies against carefully chosen opponents.
The deeper connection is that both approaches are trying to avoid blind reinforcement learning. They add structure. AlphaGo adds search. AlphaStar adds league dynamics. Robotics often adds replay buffers, value learning, demonstrations, and relabeling. LLM agents add verifiers, tests, tool traces, and preference models. The shared goal is to create a stronger teaching signal than raw outcome reward.
Why Q learning was huge
Q learning matters because it gives a way to propagate future value backward when direct search is not available.
The Bellman style target is:
\[Q_{\text{target}}(s,a)=r+\gamma \max_{a'}Q(s',a')\]The intuition is simple. The value of taking action (a) in state (s) equals the immediate reward plus the best value you can get from the next state.
This was huge historically because many problems did not allow explicit forward search. Robotics is a good example. If you cannot search a clean game tree, you can collect trajectories, store transitions, and train a value function to satisfy consistency across time.
MCTS and Q learning both move value information backward, but they do it differently.
MCTS plans forward through simulated futures, then backs up values through the search tree.
Q learning learns from experienced transitions, then backs up value through a learned recurrence.
One plans over futures the agent has not necessarily experienced. The other learns from futures the agent has visited. That distinction is key.
This is why Q learning was such a big conceptual step. It gave agents a way to learn from experience without needing to explicitly model every possible future. If you know that a future state has high value, then actions leading to that state should become more valuable. Value propagates backward through experience.
That propagation is the heart of temporal difference learning. Instead of waiting until the end of an episode and assigning the final return backward all at once, TD learning updates estimates using the difference between a current prediction and a bootstrapped target:
\[\delta = r+\gamma V(s')-V(s)\]or in action value form:
\[\delta = r+\gamma \max_{a'}Q(s',a')-Q(s,a)\]The TD error (\delta) tells the learner how surprising the transition was relative to its current value estimate. This is a way of learning from partial experience. It is not as clean as AlphaGo search, because it depends on collected trajectories and bootstrapping can become unstable, but it works in domains where forward search is unavailable.
For robotics, this matters because you often cannot cheaply search all possible motor futures. A robot has continuous actions, contact dynamics, sensor noise, and real world constraints. So the system collects transitions, stores them, learns values, and uses those values to improve behavior. The learning is less like exact planning and more like repeatedly asking: given what happened, what should my value estimate have been?
That is why the MCTS versus Q learning contrast is useful. MCTS improves a decision by simulating possible futures from the current state. Q learning improves value estimates by learning consistency across experienced transitions. Both are ways of moving future information backward. They just differ in whether the futures are searched or sampled.
Off policy data can help, but it can also poison training
The off policy discussion was one of the most practically useful parts of the episode.
Off policy data means data generated by older policies or different policies. In AlphaGo, this can happen when the replay buffer contains states from earlier versions of the model. In robotics, it can be a dataset of trajectories collected by many controllers or humans.
The danger is distribution mismatch. If your new policy would never visit a state, training heavily on that state can waste capacity or even distort behavior. You are learning what to do in parts of the world your current agent will not reach.
But off policy data can also be exactly what you want. If your policy drifts slightly away from the optimal trajectory, you need correction data. A self driving car needs to know how to recover when it veers toward the edge of the lane. A robot arm needs to know how to recover when an object slips. A Go policy needs to respond when the opponent forces a weird position.
That is why the useful off policy distribution is not arbitrary old data. It is a tube around the states your policy might reach.
Eric describes a robotics like setup:
-
Push old transition tuples into a replay buffer.
-
Use a Bellman updater or planner to compute improved targets.
-
Train the network to match those targets.
-
Use off policy estimates to reduce variance rather than blindly rewrite the objective.
His summary is that much of RL has moved toward more on policy setups because they are more stable. Off policy data is often used to shape advantages or reduce variance, not always to directly define the policy objective.
That feels very relevant for language agents. We have huge offline data, but the question is not merely whether a trajectory exists. The question is whether it lies near the behavior distribution we want the agent to learn.
The robotics analogy makes this concrete. Imagine a robot arm trained from a dataset of successful grasps. If deployment shifts slightly, the gripper may approach an object from a weird angle. If the dataset only contains perfect demonstrations, the robot may not know how to recover. Some off policy data near failure states is useful because it teaches correction. The policy learns not only the ideal trajectory, but also how to return to it.
But if the replay buffer is full of states the current robot would never reach, the learner spends capacity solving irrelevant recovery problems. In the worst case, the policy becomes good at actions that never matter and worse at the states it actually visits. This is the tension Eric is pointing at.
A useful replay buffer is not just large. It is shaped. It should contain the states the current policy visits, plus nearby perturbations that teach robustness. This is the DAGGER intuition again. The expert should label the learner’s state distribution, not only an idealized state distribution and not a totally unrelated one.
This also explains why many modern RL setups prefer on policy updates or use off policy data carefully. On policy data is expensive because you have to collect fresh trajectories. But it is stable because it matches the current policy distribution. Off policy data is efficient because you can reuse it, but it can bias the objective if the distribution is wrong.
The compromise Eric describes is to use off policy estimates to reduce variance or shape advantages rather than letting stale data fully determine the policy objective. In other words, the old data can inform the critic, the baseline, or the advantage estimate, but the main policy update should remain anchored to what the current policy actually does.
For language models, this is an underrated issue. Internet text, old model outputs, human demonstrations, synthetic traces, and tool use logs are all off policy relative to the current model. Some of that data is useful. Some of it teaches behavior the current model will never need. Some of it is actively harmful because it represents older policies, weaker tools, or different objective functions. The question is not simply more data. The question is whether the data is near the distribution we want to improve.
Forward search as an alternative to RL
One of my strongest takeaways is that search can be an alternative route to improvement.
Naive RL says: sample trajectories, score them, reinforce the successful ones.
Search says: from a state, look ahead, evaluate futures, and improve the local action distribution before committing.
In Go, this works beautifully because the environment is deterministic, the action space is finite, and the value function is grounded. In language, it is harder. But not impossible in every domain.
Mathematics, code, theorem proving, planning, and some tool use tasks have more structure than free form conversation. They often have partial verification. A proof step can be checked. A unit test can run. A plan can be simulated. A tool call can return a state.
This is why I expect forward search to keep coming back. Maybe not as literal PUCT over tokens. Maybe as search over programs, plans, subgoals, tool traces, or thought states.
Tree of Thoughts is one early version. It uses the LLM itself to generate thoughts and evaluate states. The paper explicitly leaves more advanced search algorithms such as MCTS for future work. That is exactly the open space.
The hard part is not saying “use a tree.” The hard part is defining the node, the child, the value function, and the pruning rule in a way that does not collapse into expensive prompt sampling.
This is why I think the phrase forward search should be used carefully. It can mean many things. It can mean explicit MCTS over legal moves. It can mean beam search over tokens. It can mean sampling multiple plans and scoring them. It can mean running code, checking tests, and revising. It can mean a research agent branching over experiment ideas.
The useful version depends on the domain having some local evaluability. In Go, local evaluation comes from the value function and exact rules. In code, it can come from tests, type checks, benchmarks, and static analysis. In math, it can come from proof checkers or symbolic verification. In tool using agents, it can come from environment state and task success conditions.
If there is no local evaluator, search can become expensive theater. The model samples many thoughts, judges them with the same weak intuition that generated them, and then chooses the one that sounds best. That may help sometimes, but it is not the same as grounded search.
The most promising direction is to combine language models with external evaluators. Let the model generate candidate thoughts or actions, but let the environment, verifier, unit test, simulator, or judge provide sharper feedback. That would bring language search closer to AlphaGo’s structure, where the learned policy proposes and the environment grounds.
Automated AI research is good at grinding, weaker at taste
The automated research section is the part that connects most directly to what I care about.
Eric says current models are very good at hyperparameter optimization and experiment execution. In the past, researchers would define a search space over learning rate, weight decay, network depth, and so on. Then they would run grid search or Bayesian optimization.
Coding agents can search a more open space. They can inspect gradients, rewrite a data loader, add an augmentation, change a loss term, run plots, and write a report. That is much more like a junior research assistant grinding a metric.
But Eric also says the current models are weaker at choosing the next experiment within a track, and weaker at stepping back when the whole track is wrong. They can answer a well posed question, but they often do not notice that the question itself should change.
That is the first principles gap.
LLMs can be very strong locally. They can implement, debug, plot, and optimize. But research taste often requires lateral movement. It requires asking: why are we doing this experiment at all? What is the bottleneck? Is the metric lying? Is this failure an infrastructure bug or a false hypothesis? Should we abandon this direction?
This is why Go is an interesting research environment. It has a fast outer loop. You can test whether the bot is stronger. You can measure win rate. You can verify rules. You can run small controlled experiments. It is not the same as automating all AI research, but it creates a training ground for research skills.
The big question is whether skills learned in fast verifiable domains transfer to messier domains like robotics, drug discovery, or AI training itself.
I think the answer is probably yes, but only partially. Games teach useful habits: experiment discipline, scaling intuition, debugging, search, value estimation, infrastructure. But they can also create the wrong biases. The lesson is not that games solve research. The lesson is that automated researchers need environments where feedback is fast enough to train taste.
The strongest part of current AI research agents is execution. If I know the experiment I want, a model can often help write the code, run the sweep, organize the plots, and summarize the result. That is already valuable. It changes the speed at which one person can explore an idea.
But research is not only execution. Research is also deciding which confusion is worth resolving. It is noticing that the metric is wrong. It is recognizing that an experiment is failing because of a bug rather than because the hypothesis is false. It is seeing that two promising local improvements probably will not stack. It is knowing when to stop optimizing a dead track.
Eric’s point about first principles is important here. Current models can often answer the question you ask, but they are weaker at asking whether the question is the right one. They can operate inside a frame better than they can replace the frame.
That is why automated research needs outer loops. A model optimizing a proxy metric can reward hack, overfit, or tunnel into irrelevant details. A good outer loop forces contact with reality. In Go, the outer loop can be win rate against a strong bot. In code, it can be a hidden test suite or production benchmark. In biology, it may be much slower and more expensive. In AI training, it might be downstream task performance, robustness, data efficiency, or scaling law prediction.
The harder the outer loop is to verify, the more research taste matters. If the feedback is immediate and clean, automation can go far. If the feedback is delayed, noisy, or philosophically unclear, models need stronger judgment about what intermediate signals are trustworthy.
This is where I think Go remains useful as a research training ground. It is not because Go is the same as AI research. It is because Go has enough structure to support real experiments and enough complexity to punish shallow heuristics. An automated scientist trained in such an environment might learn transferable skills: designing ablations, debugging infrastructure, estimating scaling, identifying bottlenecks, and knowing when search is giving a real signal versus an artifact.
Local improvements do not always stack
Another important point is that local improvements may not compose.
In real training systems, one researcher can find a trick that improves a metric, another can find a different trick, and the two tricks together can make things worse. Compute multipliers can be correlated. A method that helps at one scale may stop mattering at another scale.
Eric connects this to the bitter lesson. In the long run, compute and scale dominate. In the present, we still need heuristics because compute is finite and initialization is imperfect.
So research taste is partly about knowing which heuristics are worth using now, and which are temporary scaffolds that will disappear when the scale changes.
That is also why automated research is not just parallel search over ideas. Parallel agents can try many things, but someone or something still needs a top down model of what should stack, what should be isolated, and what should be abandoned.
I like the phrase compute multiplier, but it can be misleading if we imagine multipliers always multiply independently. Many algorithmic tricks exploit the same weakness. If one trick fixes the bottleneck, another trick that fixes the same bottleneck may add very little. Sometimes two tricks interact badly because they push the system in incompatible directions.
This is where the bitter lesson has a practical interpretation. Over long enough timelines, general methods that scale with compute tend to win. But in the present, we still live with constraints. We use heuristics, curricula, architectures, data filters, replay buffers, search procedures, and reward shaping because we do not have infinite compute or perfect initialization.
The taste is knowing which heuristic is a temporary scaffold and which is pointing at a deeper principle. MCTS in AlphaGo is not just a hack. It is a powerful way to create improved labels from search. Some KataGo tricks may be more contingent on hardware, data, and engineering constraints. Automated research systems need to learn that distinction.
This is also why I do not think the future of research is simply thousands of agents trying random changes. That will help, but it is not sufficient. The bottleneck becomes hypothesis selection, experiment interpretation, and synthesis. The interesting automated researcher is not only the one that runs the most experiments. It is the one that knows when an experiment changes the map.
My main takeaways
The first takeaway is that AlphaGo is an argument for better labels.
The central trick is not only self play. It is that search produces improved local targets. The system does not have to wait for a sparse final reward to explain everything.
The second takeaway is that initialization is not optional.
Starting from expert data or a working smaller setup is not cheating. It is how research becomes tractable. A system with zero pass rate may never learn. A system with a weak but real signal can hill climb.
The third takeaway is that value functions are the compression point.
A value function lets you stop searching. It turns a huge future into a scalar estimate. That is why Go becomes tractable, and why LLM reasoning remains hard. If the value function for partial thoughts is weak, search becomes expensive or misleading.
The fourth takeaway is that language search needs better units.
Tokens are usually too small. Whole answers are too large. Tree of Thoughts proposes thoughts as the unit. Tool traces, proof states, code edits, and plans may be even better units in specific domains.
The fifth takeaway is that automated AI research is already useful, but mostly inside well framed loops.
Models can run experiments, tune hyperparameters, generate plots, and debug implementation issues. They are weaker at deciding that the current frame is wrong. That is where first principles reasoning and research taste still matter.
The sixth takeaway is that off policy data is not good or bad in isolation.
It depends where the data sits relative to the states your current policy can reach. A replay buffer near the policy distribution can teach recovery. A replay buffer far away can waste capacity.
The seventh takeaway is that test time scaling and distillation form a powerful cycle.
Search spends compute to improve behavior. Training distills that behavior into the network. Then future search starts from a stronger place. That loop is one of the cleanest pictures of how reasoning and learning can compound.
The eighth takeaway is that Tree of Thoughts is best understood as a search framework, not just a prompting trick.
Its key move is to make generation, evaluation, and search separate pieces. That separation matters because each part can improve independently. A better thought generator gives better candidates. A better evaluator gives better pruning. A better search algorithm spends compute more intelligently.
The ninth takeaway is that LLM reasoning needs grounded evaluators.
Self evaluation is useful, but it is not the same as a grounded value function. The strongest future systems will probably combine language search with external checks: tests, simulators, tools, proof verifiers, environment feedback, or learned critics trained on real outcomes.
The tenth takeaway is that the unit of reasoning is a research problem.
In Go, the unit is a legal move. In Tree of Thoughts, the unit is a thought. In coding agents, the unit may be a patch, a function, a failing test, or a tool trace. In automated research, the unit may be an experiment. Choosing this unit badly can make search useless. Choosing it well can make reasoning tractable.
The open question
The question I keep coming back to is this:
Can we build an AlphaGo like improvement loop for language agents without pretending language is Go?
The answer cannot be literal MCTS over tokens. The child space is too large. Exact child revisits are rare. Values are fuzzy. Many tasks do not have a clean simulator.
But the deeper pattern still seems right.
We need systems that can generate alternatives, evaluate partial progress, backtrack, relabel their own behavior with stronger targets, and distill that improvement into future policy.
That might look like Tree of Thoughts for toy reasoning tasks. It might look like tool trace search for agents. It might look like verifier guided proof search for math. It might look like replay plus relabeling for robotics. It might look like automated research loops where models propose experiments, run them, and learn which research moves actually improve outer loop performance.
AlphaGo remains important because it gives a working example of the full loop:
-
Search makes a policy better.
-
The better policy becomes training data.
-
The neural network absorbs the search.
-
The next search starts stronger.
-
The system compounds.
That is the part I find most interesting. Not AlphaGo as a historical Go bot, but AlphaGo as a template for turning expensive deliberation into cheap intuition.
That template is still not fully solved for LLMs. But it feels like one of the roads we keep circling back to.
The post could be summarized in one sentence: the future is not only bigger policies trained on sparse rewards, but systems that can turn deliberation into better labels.
That is what AlphaGo did cleanly. That is what Tree of Thoughts gestures toward for language. That is what robotics tries to do with replay, relabeling, and value learning. That is what automated research agents will need to do with experiments.
The hard part is grounding. Search without grounding becomes expensive sampling. RL without grounding becomes sparse reward noise. Automated research without grounding becomes metric chasing. But when the loop is grounded, the system can improve itself in a way that feels qualitatively different from passive imitation.
That is the part of the episode I keep thinking about. AlphaGo was not only a Go machine. It was an existence proof for a pattern of learning where a system uses computation to create better supervision for itself. If we can find the right version of that pattern for language agents and research agents, the next jump may not come from a single new model architecture. It may come from a better loop.